
1. はじめに:AI創薬のモデル構築でつまずく「ハイパーパラメータ」
AI創薬の現場では、QSAR(化学構造と生物活性の定量的関係)モデルやADMET予測モデル、生成AIによる分子設計モデルなど、機械学習・深層学習を活用する場面が急速に増えています。一方で、これらのモデルの性能を決定づける重要な要素として「ハイパーパラメータ(学習前に人間が決める設定値)」の最適化が常につきまといます。
勾配ブースティングの木の深さ、ニューラルネットワークの層数や学習率、分子記述子の選択といったハイパーパラメータの組み合わせは膨大であり、手動の試行錯誤では網羅できません。そこで近年、創薬関連の機械学習パイプラインでも採用例が増えているのが、本記事で紹介するOptunaです。Optuna自体は創薬専用のAIツールではなく、機械学習・深層学習のハイパーパラメータ最適化を担う汎用のPython製OSSですが、QSARモデルやADMET予測モデルの構築を支援する場面で広く活用されています。本記事では、Optunaの設計思想、主要機能、そしてQSARtunaやDeepMolといった創薬関連ツールでの採用例まで、医療関係者・研究者向けにわかりやすく解説します。
2. Optunaとは:Preferred Networksが開発したPython製OSS
Optunaは、日本のPreferred Networks社が2018年12月にβ版を公開したオープンソースのハイパーパラメータ自動最適化フレームワークです。Python製の軽量ライブラリでありながら、機械学習・深層学習の主要フレームワークとシームレスに連携でき、ローカルの試行錯誤から大規模分散最適化まで一貫したコードで扱える点が大きな特徴です。
2020年には正式版v1.0がリリースされ、その後も活発な開発が続いています。GitHubの公式リポジトリ(github.com/optuna/optuna)は機械学習コミュニティで広く支持されており、有力なOSSの一つとして定着しています。
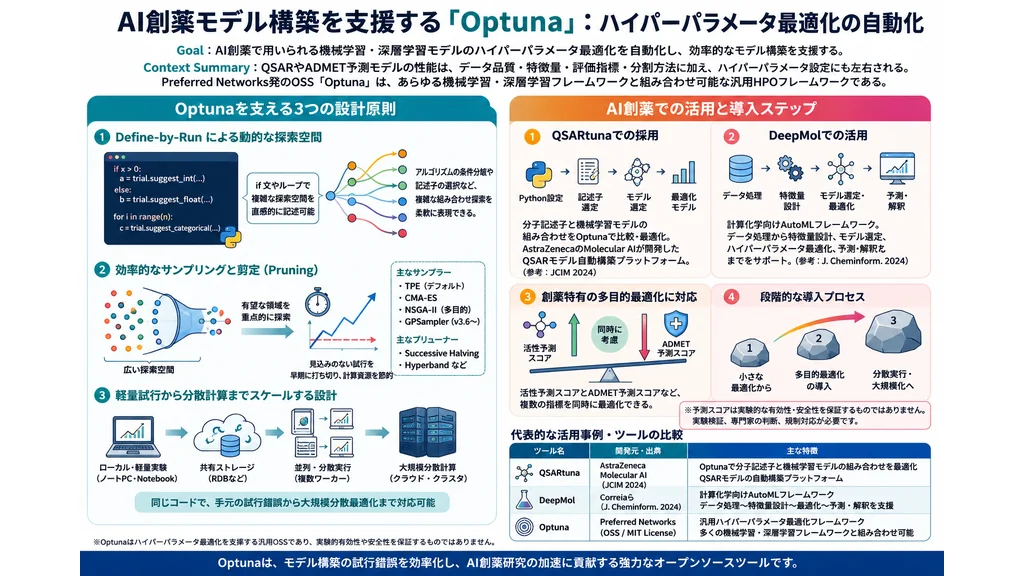
Optunaの設計思想を解説した論文「Optuna: A Next-generation Hyperparameter Optimization Framework」(Akibaら、KDD 2019)では、次世代の最適化フレームワークが備えるべき3つの設計基準が提唱されました。①Define-by-Run APIによる動的な探索空間の構築、②効率的なサンプリングと剪定アルゴリズム、③軽量実験から分散計算まで対応する柔軟なアーキテクチャ、の3点です。
3. Optunaを支える3つの設計原則
3.1. Define-by-Run APIで探索空間を動的に書ける
従来のハイパーパラメータ最適化ツールは、探索する範囲を事前にすべて静的に定義する必要がありました。一方Optunaは、目的関数(objective関数)の実行時に探索空間を動的に組み立てられるDefine-by-Run方式を採用しています。これにより、Pythonの条件分岐やループをそのまま書ける感覚で、複雑な探索空間を直感的に表現できます。
たとえば「アルゴリズムがランダムフォレストならば木の深さを探索する」「ニューラルネットワークならば層数と活性化関数を探索する」といった、ツリー状に分岐する探索空間も、Pythonのif文一つで自然に書けます。これは、創薬モデルのように「分子記述子の種類」と「機械学習アルゴリズム」を組み合わせ最適化したい場面で特に強力です。
3.2. 効率的なサンプリングと剪定アルゴリズム
Optunaは、有望な領域を重点的に探索するベイズ最適化(TPESampler)や、進化計算ベースの最適化(CmaEsSampler)、多目的最適化(NSGAIISampler)など、複数の主要なアルゴリズムを切り替えて利用できます。v3.6からは、ガウス過程ベースのベイズ最適化を行うネイティブのGPSamplerも追加されました。デフォルトでは、過去の試行結果に基づき確率分布を更新するTPE(Tree-structured Parzen Estimator)が使われます。
さらに、有望でない試行を学習の途中で早期に打ち切る「剪定(Pruning)」機能を備えています。これにより、深層学習のように1試行が数十分〜数時間かかるケースでも、計算リソースを大幅に節約できます。代表的な剪定アルゴリズムには、MedianPruner、Successive Halving、Hyperbandなどがあります。
3.3. 軽量試行から分散計算までスケールする設計
Optunaは、Jupyter Notebook上の手元実験から、数十〜数百ワーカーによる分散最適化まで、同じコードで対応できる設計になっています。リレーショナルデータベース(RDB)を最適化履歴のストレージとして使う構成にすれば、複数マシン・複数プロセスからの並列実行が容易に実現します。創薬研究の社内クラスタやクラウド計算リソースにスケールアウトする際にも扱いやすい設計です。
4. AI創薬研究でOptunaが採用される背景
創薬モデルは、データセットが小規模・偏在しがちで、しかも多くの場合に「分子記述子の選択」「アルゴリズムの選択」「各アルゴリズムのハイパーパラメータ」という三層の意思決定が同時に必要になります。Optunaが備える次の特性は、こうした創薬特有の課題と相性が良く、創薬関連の機械学習パイプラインでも採用例が見られる理由となっています。
- 条件付き探索空間:記述子・モデル・パラメータを階層的に最適化できる
- 多目的最適化:活性予測スコアやADMET予測スコアなど、複数の指標を目的関数に含めた多目的最適化を設計できる
- 剪定機能:交差検証の途中で見込みのない試行を打ち切り、計算時間を圧縮できる
- 可視化:最適化履歴、パラメータ重要度、並行座標プロットなどで結果を解釈できる
- 主要フレームワークとの連携:scikit-learn、PyTorch、TensorFlow、LightGBM、XGBoostなどとシームレスに統合
これらの特性が、後述するQSARtunaやDeepMolといった創薬関連のAutoMLツールがOptunaを最適化エンジンとして採用している背景となっています。
5. AI創薬でのOptuna活用事例
5.1. QSARtuna:AstraZenecaのQSAR自動構築プラットフォーム
QSARtuna(キューサーチューナ)は、AstraZenecaのMolecular AI部門が開発し、2024年7月にJournal of Chemical Information and Modeling誌で発表したQSARモデル自動構築プラットフォームです。Optuna、scikit-learn、RDKit、Chempropといった主要ライブラリの上に構築されており、分子記述子と機械学習アルゴリズムの組み合わせを自動で比較・選定できる点が大きな特徴です。
QSARtunaは3段階のワークフローを採用しています。第1段階で記述子(ECFP、MACCS Keys、ZScalesなど)とアルゴリズム(ランダムフォレスト、XGBoost、SVRなど)の組み合わせをOptunaで最適化し、第2段階で最良モデルを選定・評価、第3段階のProd-buildで訓練と検証データを統合した最終モデルを構築します。実際のAstraZeneca社内では、生成AIによる分子設計ツールREINVENTと組み合わせて、de novo創薬パイプラインに組み込まれています。
5.2. DeepMol:計算化学向けAutoMLフレームワーク
DeepMolは、Correia・Capela・Rochaらが2024年12月にJournal of Cheminformatics誌で発表した、計算化学向けの自動機械学習・深層学習フレームワークです。22件のベンチマークデータセットで、人手による特徴量設計・モデル選択を経た既存パイプラインに匹敵する性能を達成したと報告されています。
DeepMolの中核には最適化エンジンとしてOptunaが組み込まれており、データ前処理から特徴量設計、モデル選択、ハイパーパラメータ調整までを一気通貫で自動化します。創薬・毒性予測といった目的に特化して設計されている点が、汎用AutoMLとの差別化要因です。
5.3. その他の応用シナリオ
QSARtunaやDeepMolのような完成形ツール以外にも、自前モデルでOptunaを活用する場面は数多くあります。たとえばLightGBMやXGBoostを使った疾病予測モデルの構築では、Optunaで木の深さ・学習率・正則化パラメータを最適化することで、デフォルト設定よりも性能が向上した事例が複数の研究で報告されています。ただし結果はデータセット、探索空間の設計、評価指標、データ分割方法に依存するため、性能向上が必ず得られるとは限らない点には留意が必要です。深層学習モデルでも、optuna-integrationパッケージのPyTorch Lightning向けコールバックを使うことで、層数・ドロップアウト率・学習率スケジュールなどを比較的少ない記述量で自動チューニングできます。
6. Optunaの基本的な使い方とコード例
Optunaの導入は、pip install optunaの一行で完了します。最小のサンプルコードを示します。
import optuna
def objective(trial):
x = trial.suggest_float("x", -10, 10)
y = trial.suggest_int("y", -10, 10)
return (x - 2) ** 2 + (y + 3) ** 2
study = optuna.create_study(direction="minimize")
study.optimize(objective, n_trials=100)
print(study.best_value, study.best_params)QSARモデルを想定した場合の使い方は、おおよそ次のようなコードになります。trial.suggest_*で記述子やアルゴリズムを動的に選び、交差検証スコアを返す目的関数を作るのが基本です。
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_val_score
def objective(trial):
n_estimators = trial.suggest_int("n_estimators", 50, 500)
max_depth = trial.suggest_int("max_depth", 2, 32, log=True)
min_samples_split = trial.suggest_float("min_samples_split", 0.01, 0.5)
model = RandomForestClassifier(
n_estimators=n_estimators,
max_depth=max_depth,
min_samples_split=min_samples_split,
random_state=42,
)
return cross_val_score(model, X, y, cv=5).mean()
study = optuna.create_study(direction="maximize")
study.optimize(objective, n_trials=100)剪定機能を使う場合は、目的関数の中でtrial.report()とtrial.should_prune()を呼び出します。エポックごとに中間スコアを報告し、見込みがなければ早期に試行を打ち切る、という流れです。なお、scikit-learnのcross_val_score()を呼ぶだけの構成では、交差検証の途中で自動的に剪定が発火することはありません。剪定を活かすには、自前の学習ループや、Optuna公式が別パッケージoptuna-integrationとして提供するPyTorch Lightning / XGBoost / LightGBM 用のコールバックを通じてtrial.report()を併用する必要があります。さらに最適化結果はoptuna.visualizationで履歴やパラメータ重要度をプロットでき、対話的に分析できます。
7. Optuna導入の利点と注意点
Optunaを創薬研究のワークフローに取り込む際の利点と注意点を整理しておきます。
- 利点①記述量が少ない:Pythonの自然な構文で探索空間を表現でき、学習コストが低い
- 利点②高い拡張性:scikit-learn、PyTorch、TensorFlow、LightGBM、XGBoostなどと統合可能
- 利点③コミュニティが活発:日本語の公式ドキュメント・解説記事も充実
- 注意①探索空間の設計が肝:範囲設定が不適切だと最適化性能が大きく下がる
- 注意②高次元で性能低下:パラメータ数が極端に多い場合、ベイズ最適化の利点が薄れる
- 注意③乱数の管理:再現性を担保するには
samplerのシードと前処理の乱数シードを揃える必要がある - 注意④計算コストは依然として存在:剪定を活用しても、大規模探索ではGPU・CPU資源の確保が前提
- 注意⑤AI予測は最終確証ではない:Optunaで最適化したQSAR・ADMETモデルの予測値は、あくまで候補化合物の選定や優先順位付けを支援する参考情報であり、実験的な有効性・安全性・臨床的妥当性を保証するものではない。最終的には実験検証、専門家の判断、規制対応が不可欠
とくに注意点①は実務で大きな影響があります。たとえば学習率を1e-5〜1.0のように広く取り、対数スケール(log=True)を指定するかどうかで結果は大きく変わります。創薬モデルに固有の知見(記述子の選択、データ分割方法など)を踏まえた探索空間設計が、Optuna活用の成否を分けます。
8. AI創薬研究へのOptuna導入ステップ
これから創薬研究にOptunaを取り入れる場合、次のような段階的導入をおすすめします。
- Step 1:既存のscikit-learnベースのQSARモデルに対し、まず1〜2個のハイパーパラメータだけ最適化してみる
- Step 2:分子記述子の種類とアルゴリズムを条件付き探索空間でまとめて最適化
- Step 3:学習ループや専用コールバックの中で
trial.report()/trial.should_prune()を呼び、剪定を有効化して計算時間を圧縮する - Step 4:QSARtunaやDeepMolなどの上位ツールに移行、もしくは社内パイプラインを構築
- Step 5:活性予測スコアとADMET予測スコアを同時に扱う多目的最適化や、複数ワーカーでの分散実行に拡張
このように小さく始めて段階的に広げることで、無理なく自分の研究フローに馴染ませることができます。
9. まとめ:Optunaは創薬AIの「縁の下のチューニング担当」
Optunaは、Preferred Networksが開発したPython製のハイパーパラメータ最適化OSSです。創薬専用のAIツールではなく汎用フレームワークですが、AI創薬モデルの構築・改善においても採用例が増え、有力な選択肢の一つとして定着しつつあります。Define-by-Run APIによる柔軟な探索空間、TPEや剪定アルゴリズムによる効率的な最適化、そしてQSARtunaやDeepMolといった創薬関連ツールへの組み込み実績が、こうした採用の背景にあります。
創薬研究者にとって、Optunaは「縁の下のチューニング担当」として静かに性能を底上げしてくれる存在です。一方で、Optunaが最適化するのはモデルのハイパーパラメータであって、化合物の実際の有効性・安全性ではないという点は常に意識する必要があります。生成AI、構造予測、ADMET予測など、創薬AIのモデルが多様化していく今後も、その活躍の場はさらに広がっていくでしょう。本記事を起点に、ぜひ自身のQSARモデルやADMET予測モデルにOptunaを取り入れ、実験検証と組み合わせて活用してみてください。
参考文献・リンク
- Optuna公式サイト:https://optuna.org/
- Optuna公式ドキュメント(日本語):https://docs-ja.optuna.org/
- Optuna GitHubリポジトリ:https://github.com/optuna/optuna
- Optuna論文(Akibaら, KDD 2019):https://arxiv.org/abs/1907.10902
- QSARtuna論文(Mervinら, J. Chem. Inf. Model. 2024, 64(14), 5365–5374):https://pubs.acs.org/doi/10.1021/acs.jcim.4c00457
- QSARtuna GitHubリポジトリ:https://github.com/MolecularAI/QSARtuna
- DeepMol論文(J. Cheminform., 2024):https://jcheminf.biomedcentral.com/articles/10.1186/s13321-024-00937-7
- Preferred Networks Tech Blog(日本語解説):https://tech.preferred.jp/ja/blog/an-introduction-to-hyperparameter-optimization-with-optuna-ieice/
免責事項
本記事は、Optunaに関する情報提供を目的として作成されたものです。記事の内容は、公開時点で入手可能な文献・情報に基づいていますが、技術の進歩や新たな知見により、情報が変更される場合があります。記事に記載されたソフトウェアの使用結果や、それに基づく研究成果について、筆者および本ブログは一切の責任を負わないものとします。実際の創薬研究や臨床応用にあたっては、必ず最新の文献・公式ドキュメントを確認し、専門家の助言を得てください。
本記事は生成AIを活用して作成しています。内容については十分に精査しておりますが、誤りが含まれる可能性があります。お気づきの点がございましたら、コメントにてご指摘いただけますと幸いです。
Amazonでこの関連書籍「Optunaによるブラックボックス最適化」を見る