
1. はじめに:カテゴリ変数をそのまま扱えるGBDT「CatBoost」
これまでの記事では、記述子QSAR(分子の構造を数値化して活性を予測する手法)の定番としてXGBoost、大規模データに強い高速実装としてLightGBMを取り上げました。今回紹介するCatBoostは、これらと同じ勾配ブースティング決定木(Gradient Boosting Decision Tree:GBDT、決定木を逐次的に積み重ねる手法)の実装でありながら、「カテゴリ変数(分類を表す質的な特徴量)をそのまま入力できる」という独自の強みを持つライブラリです。
AI創薬の現場では、分子記述子のような数値だけでなく、原子の種類・官能基の有無・結合の種類といったカテゴリ的な特徴量を扱う場面が数多くあります。本記事では、CatBoostの仕組みと強み、AI創薬での具体的な活用例、そしてXGBoost・LightGBMとの使い分けまでをstep-by-stepで解説します。なお、CatBoostはAI創薬専用ツールではなく汎用のGBDTライブラリであり、その予測は研究の意思決定を支援するもので、実験的検証や専門家の判断を置き換えるものではない点を最初におさえておきましょう。
2. CatBoostとは?Yandexが開発したGBDT実装
CatBoostは、ロシアのYandex社が開発したオープンソースの勾配ブースティングライブラリです。名前は「Categorical(カテゴリの)+Boosting(ブースティング)」に由来し、カテゴリ変数の処理に特化していることを表しています。中核となる手法は、Prokhorenkovaらの論文「CatBoost: unbiased boosting with categorical features」(arXiv:1706.09516、NeurIPS 2018で発表)にまとめられています。
この論文が提示した技術的な柱は2つあります。1つはカテゴリ変数を扱うための新しいアルゴリズム、もう1つが「Ordered Boosting(順序付きブースティング)」と呼ばれる学習手法です。いずれも、従来のGBDT実装に共通して存在する「予測シフト(prediction shift)」という一種のターゲットリーク(目的変数の情報が学習に漏れ込み、性能を過大評価させる現象)を抑えることを目的に設計されています。これにより、論文中のベンチマークでは、多くのデータセットで他の公開実装を上回る精度が報告されています。
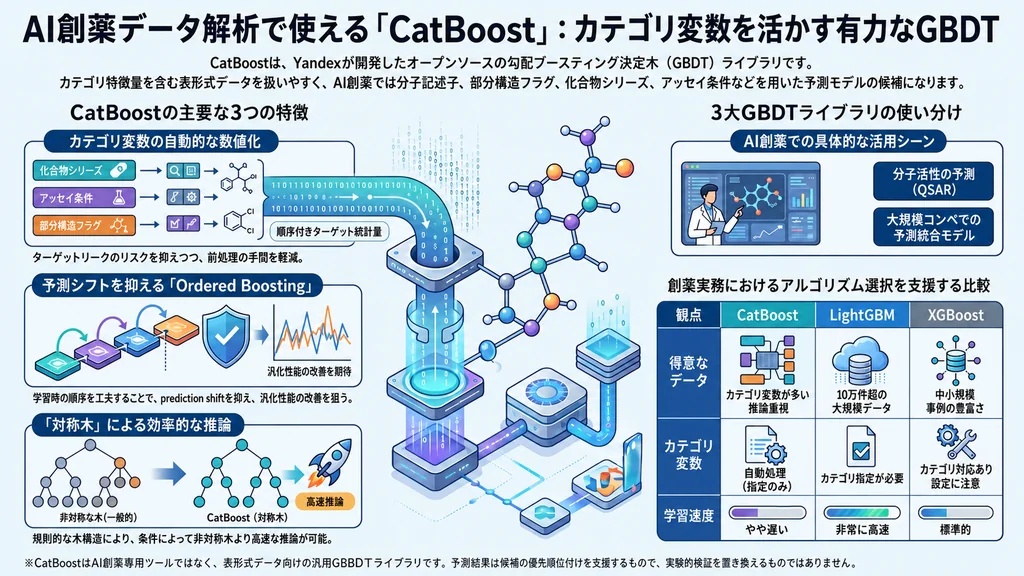
3. 強み①:カテゴリ変数を内部で自動的に数値化
CatBoost最大の特徴は、カテゴリ変数を内部で自動的に数値へ変換してくれる点です。従来のXGBoostではOne-Hotエンコーディング(各カテゴリを0と1の列に展開する前処理)などが一般的でした。現在のXGBoostにもカテゴリ特徴量を扱う機能はありますが、CatBoostはカテゴリ特徴量の処理を中核的な特徴として設計されており、「どの列がカテゴリ変数か」を指定するだけで前処理の手間を大きく減らせます。
変換の基本は、各カテゴリに対応する目的変数の統計量(ターゲット統計量)を用いたエンコーディングです。ただし単純な平均ではターゲットリークが起きるため、CatBoostはOrdered Target Statistics(順序付きターゲット統計量)という工夫を採用しています。データにランダムな順序を与え、「あるサンプルより前に現れたデータだけ」を使って統計量を計算することで、自分自身の答えを使ってしまう問題を回避します。あわせて、出現頻度の低いカテゴリには全体平均を混ぜるスムージング(平滑化)を施し、過学習(学習データに適合しすぎて未知データで精度が落ちる現象)を抑えます。さらにCatBoostは、カテゴリ特徴量どうし、あるいはカテゴリ特徴量と数値特徴量を組み合わせた統計量も内部で生成し、特徴量間の関係を捉えます。
分子記述子を用いた予測モデルでは、RDKitなどで抽出した部分構造フラグ、官能基の種類・数、骨格クラス(Bemis–Murcko骨格など)、化合物シリーズ、アッセイ条件、ライブラリIDなど、カテゴリ的または離散的な特徴量を扱う場合があります。CatBoostはこのような表形式の混合特徴量を扱いやすいため、ケモインフォマティクス(化学情報学)の前処理・QSARモデル構築における有力な選択肢となります。なお、原子や結合そのものの種類は、分子グラフを直接扱うグラフニューラルネットワーク(GNN)ではノード・エッジの特徴量として扱われることが多く、CatBoostのような表形式モデルでは「分子から抽出したカテゴリ的特徴量」として設計する点に注意が必要です。
4. 強み②:Ordered Boostingと対称木による安定した学習
CatBoostの基本学習器は、Oblivious Decision Tree(対称木)です。通常の決定木はノードごとに異なる条件で分割しますが、対称木は「同じ深さでは全ノードが同じ条件で分割する」という制約を持ちます。一見すると窮屈な構造ですが、これが2つの利点を生みます。
1つは過学習の抑制です。分割の自由度が制限されるぶん表現力が抑えられ、強い正則化(モデルを単純に保つ働き)として機能します。もう1つは推論の高速化です。木の構造が規則的なため、葉の番号をビット演算でまとめて計算でき、非対称木に比べて予測を高速に行えます。CatBoost公式や技術解説では、対称木により非対称木と比べて最大で10倍程度速い推論が可能で、GPUを使った並列化とも相性が良いと説明されています(高速化の度合いはデータやハードウェアに依存します)。
さらに前述のOrdered Boostingは、勾配(予測誤差に相当する量)を計算する際にも「そのサンプルより前のデータだけで学習したモデル」を使うことで、予測シフトを抑えます。学習にやや時間がかかる一方、汎化性能(未知データへの当てはまりの良さ)の高いモデルを作りやすいのが、CatBoostの設計思想です。ただし対称木は表現力に制約があるため、特徴量間の複雑な相互作用が支配的なデータでは、非対称木のLightGBMやXGBoostのほうが当てはまりが良い場合もあります。万能ではない点には留意が必要です。
5. AI創薬におけるCatBoostの活用
5.1 分子記述子を用いたQSAR・物性予測
AI創薬では、分子記述子(molecular descriptors、化合物の構造や性質を数値化した特徴量)を入力に、活性や物性を予測するQSAR(定量的構造活性相関)モデルが広く使われます。記述子には、分子量や原子数などの基本物性、部分構造や経路の有無を表すフィンガープリント(ビット列・カウントベクトル)、トポロジー記述子、3次元構造に基づく表面積・体積・立体配置に関する特徴量など、多様な種類があります。CatBoostは、これらの数値記述子に加えてカテゴリ的な特徴を混在させても扱えるため、前処理を簡素化しつつ精度を狙える点が実務的な利点です。
5.2 NeurIPS 2024 BELKAコンペでのスタッキング活用
具体的な活用例として、NeurIPS 2024の創薬コンペ「BELKA(Big Encoded Library for Chemical Assessment)」が挙げられます。これはLeash Biosciences社が提供したDNAエンコードライブラリ(DEL:各化合物にDNAタグを結合させ、大量の化合物を一括でスクリーニングする技術)由来の大規模データを用いるKaggleコンペで、約1.33億の小分子とBRD4・sEH・HSAの3標的に関する結合予測が課題でした。背景となる実験では、約36億件規模の物理測定が行われたと報告されています。
このコンペに参加したあるチームの解法では、1DCNN・ChemBERTa・LightGBMなど複数のベースモデルを構築し、それぞれの予測値を入力としてCatBoostで最終予測をまとめるスタッキング(複数モデルの出力を別モデルで統合する手法)のメタモデルとしてCatBoostが用いられたことが、参加者の解説記事で報告されています。表形式の中規模な特徴量(各モデルの予測値)を安定して統合する用途は、CatBoostが力を発揮しやすい場面の一つです。なお、コンペ以外でも、抗がん剤の併用効果(薬剤シナジー)予測にCatBoostを用いた査読論文(PMC, 2025年)が報告されるなど、創薬関連での活用が広がっています。
6. XGBoost・LightGBMとの比較と使い分け
AI創薬の現場では、XGBoost・LightGBM・CatBoostの3つが代表的な選択肢です。いずれも優れたGBDT実装であり、「どれが常に最良か」は一概に決められませんが、設計上の特徴には次のような違いがあります。
📊 3大GBDTライブラリ 比較早見表
| 観点 | CatBoost | LightGBM | XGBoost |
|---|---|---|---|
| 木の構造 | 対称木 | 葉単位(Leaf-wise) | 階層単位(Level-wise) |
| カテゴリ変数 | 自動処理(指定のみ) | 整数指定で対応 | 前処理が一般的(近年ネイティブ対応も) |
| 学習速度 | やや遅い傾向 | 高速(大規模に強い) | 中程度 |
| 推論速度 | 高速(対称木) | 速い | 標準的 |
| 向くデータ | カテゴリ変数が多い/推論を多用 | 10万化合物超の大規模 | 中小規模/事例重視 |
※ 精度・速度はデータの規模や化学空間、評価方法で変わります。最終的には自分のデータで比較検証することが重要です。
使い分けの目安としては、カテゴリ変数が多く前処理を減らしたい場合や、学習済みモデルで高速な推論を繰り返したい場合はCatBoost、10万化合物を超えるような大規模データで学習速度を最優先するならLightGBM、豊富な事例とチューニング情報を重視するならXGBoost、というのが一つの基準になります。とはいえ最良の手法はデータの規模・化学空間・評価方法で変わるため、複数を比較対象に入れて自分のデータで検証することをおすすめします。
7. CatBoostの実装ポイント
CatBoostはApache-2.0ライセンスのオープンソースで、pipで簡単に導入でき(pip install catboost)、scikit-learnに近いインターフェースで使えます(商用・社内利用の際は最新のライセンス条項をご確認ください)。最大のポイントは、カテゴリ変数の列番号をcat_featuresに渡すだけで自動処理が有効になることです。分子記述子を使った活性予測(回帰)の最小例を示します。
🐍 CatBoostRegressorによるQSAR活性予測(最小例)
from catboost import CatBoostRegressor
from sklearn.model_selection import train_test_split
# X: 分子記述子などの特徴量, y: 活性値
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
# カテゴリ変数の列インデックスを指定
# 例:化合物シリーズ、骨格クラス、アッセイID、置換基タイプなど
cat_features = [0, 2, 5]
model = CatBoostRegressor(
iterations=1000, # 決定木の本数(early stopping併用)
depth=6, # 木の深さ(6〜10が目安)
learning_rate=0.05, # 学習率(小さくして本数を増やすと安定)
l2_leaf_reg=3, # L2正則化(過学習の抑制)
loss_function='RMSE',
cat_features=cat_features,
early_stopping_rounds=50,
verbose=100,
)
model.fit(X_train, y_train, eval_set=(X_test, y_test))
predictions = model.predict(X_test)
主要なハイパーパラメータは、iterations(木の本数、early stoppingと併用して1000〜2000程度)、depth(木の深さ、6〜10)、learning_rate(学習率、0.01〜0.1)、l2_leaf_reg(L2正則化、3〜10)です。SHAP値(各特徴が予測へ与えた寄与を見る手法)による重要度の可視化にも対応しており、どの記述子が予測に効いているかを解釈できます。ただしSHAPはあくまでモデル解釈の補助であり、重要と示された記述子が薬効の原因であるとは限らないため、化学的・生物学的な妥当性は別途確認が必要です。また、CatBoostは数値特徴量の欠損値(記述子が計算できなかった場合など)を内部で処理できるため、欠損補完の前処理を省けるのも実務上の利点です(カテゴリ特徴量の欠損は、文字列カテゴリとして扱う・事前に置換するなど、データ型を整える注意が必要です)。
注意点として、QSARやADMET予測では評価方法そのものが結論を左右します。化合物をランダムに分割すると似た構造が訓練・テスト両方に入り、性能を過大評価しがちです。骨格(スキャフォールド)単位で分割するスキャフォールド分割や独立データでの外部検証を行い、モデルが信頼できる化学空間の範囲(適用範囲:applicability domain)を確認しましょう。入力データの品質や活性値の測定条件のばらつきも、予測の信頼性を大きく左右します。
8. まとめ:カテゴリ変数を含む分子データの有力な選択肢
CatBoostは、カテゴリ変数をネイティブに扱える勾配ブースティングライブラリです。Ordered Target StatisticsとOrdered Boostingによりターゲットリークを抑え、対称木による安定した学習と高速な推論を両立します。分子記述子を用いたQSARや物性予測、BELKAコンペで見られたスタッキングのメタモデルなど、創薬の幅広い場面で「まず比較対象に入れるべき有力なベースライン」として活用できます。
一方で、CatBoostが常に最良というわけではありません。CatBoostは特徴量設計済みの表形式データに対する教師あり学習モデルであり、分子グラフ・3D構造・タンパク質配列・複合体構造を直接扱うGNN・Transformer・ドッキングなどとは役割が異なります。学習時間はやや長くなる傾向があり、課題によってはLightGBMやXGBoost、あるいはグラフニューラルネットワークが適することもあります。XGBoost・LightGBMと並べて自分のデータで比較し、評価方法とデータ品質を吟味したうえで選ぶことが、信頼できる予測モデルへの近道です。そして、ここで紹介した予測はいずれも候補化合物の優先順位付けや仮説生成を支援するものであり、実験的検証・専門家の判断を置き換えるものではない点を、最後に改めて強調しておきます。
参考リンク
- CatBoost 公式ドキュメント:https://catboost.ai/docs/en/
- CatBoost GitHubリポジトリ:https://github.com/catboost/catboost
- Prokhorenkova et al.「CatBoost: unbiased boosting with categorical features」(NeurIPS 2018, arXiv:1706.09516):https://arxiv.org/abs/1706.09516
- NeurIPS 2024 – Predict New Medicines with BELKA(Kaggle):https://www.kaggle.com/competitions/leash-BELKA
- Anticancer drug synergy prediction based on CatBoost(PMC, 2025):https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12190655/
- CatBoost Enables Fast Gradient Boosting on Decision Trees Using GPUs(NVIDIA Technical Blog):https://developer.nvidia.com/blog/catboost-fast-gradient-boosting-decision-trees/
免責事項
本記事は、CatBoostおよびQSAR・AI創薬に関する情報提供を目的として作成されたものです。記事の内容は、公開時点で入手可能な文献・情報に基づいていますが、技術の進歩や新たな知見により、情報が変更される場合があります。記事に記載されたソフトウェアの使用結果や、それに基づく研究成果について、筆者および本ブログは一切の責任を負わないものとします。実際の創薬研究や臨床応用にあたっては、必ず最新の文献・公式ドキュメントを確認し、専門家の助言を得てください。
本記事は生成AIを活用して作成しています。内容については十分に精査しておりますが、誤りが含まれる可能性があります。お気づきの点がございましたら、コメントにてご指摘いただけますと幸いです。なお、本記事の内容に基づいて生じたいかなる損害についても、当サイトは責任を負いかねます。
Amazon関連書籍 Amazonでこの関連書籍「スッキリわかるPythonによる機械学習入門 第2版 (スッキリわかる入門シリーズ)」を見る
関連YouTubeリンク