
はじめに:権限の枠組みの次は「何を渡さないか」
第5回では、Claude Codeの権限モードとsettings.jsonを使って、AIにどこまで操作を許すかを設計する枠組みを整理しました。第6回となる本記事は、第2章(事前準備と安全)の締めくくりにあたります。テーマは、Claude Codeに「そもそも渡してはいけないデータ」と「渡すときに必要な加工」です。
権限管理を丁寧に設計しても、AIに渡すプロンプトやファイルそのものに、APIキーや患者情報、未公開の研究データといった機密が含まれていれば、リスクは権限の外側で発生してしまいます。本記事では、Python経験者の非エンジニア向けに、Claude Codeを業務・研究・教育で使うときに「何を渡さないか」「どう守るか」を一歩ずつ整理します。
この記事のゴール
本記事を読み終えると、次のことができるようになります。
- Claude Codeに不用意に渡してはいけない4種類のデータ(APIキー、患者情報、学生情報、未公開研究データ)を区別できる
- APIキーを環境変数や
.envファイルで管理し、コードやプロンプトに書かない運用にできる .gitignoreを最初に整え、機密ファイルをGit追跡対象から外せる- 医療法・個人情報保護法・研究倫理指針との関係を意識し、所属機関の規程と照合する習慣を持てる
- 万一データを渡してしまった場合の初動対応の手順を理解できる
本記事は法的助言ではありません。最終的な判断は、所属機関のコンプライアンス窓口・倫理委員会・情報セキュリティ部門と相談しながら進めてください。
なぜ「渡さない」を最初に決める必要があるのか
Claude Codeに渡された情報は、原則としてAnthropicのサービスに送信されて応答が生成されます。データの保持期間や学習利用の可否、Zero Data Retention(受信データを保持しない構成)の適用有無は、利用プラン・契約形態・使用モデル・エンタープライズ契約の内容によって異なります。実際の方針は、Anthropic公式ドキュメントとご自身の契約条件を必ず最新の状態で確認したうえで判断してください。本記事ではこれ以上踏み込まず、いずれの構成でも共通する「自分の手元から外に出る」という性質に絞って整理します。一度外に出た情報は、削除を依頼できる場合でも、すでに参照されたり、ログに残ったりした可能性を完全には消せません。
そのため、機密情報を扱う研究・医療・教育の現場では、「権限管理でブロックする」のではなく「そもそも渡さない」という設計を最初に置くのが基本になります。第5回で扱った権限モードは、AIに行わせる操作の範囲を制限する仕組みでしたが、本記事の「渡さない」は、その手前のデータ選別の段階の話です。
もうひとつ重要なのは、Claude Codeのプロンプトに直接書かなくても、AIが読みに行くファイルやフォルダの中身は、ほぼ確実に解析の対象になるという点です。「フォルダごと開いた」「ファイルを編集してもらった」「ログを要約してもらった」という操作は、すべて「そのファイルの中身をAIに渡した」のと同じです。起動するフォルダの中身を、毎回意識する必要があります。
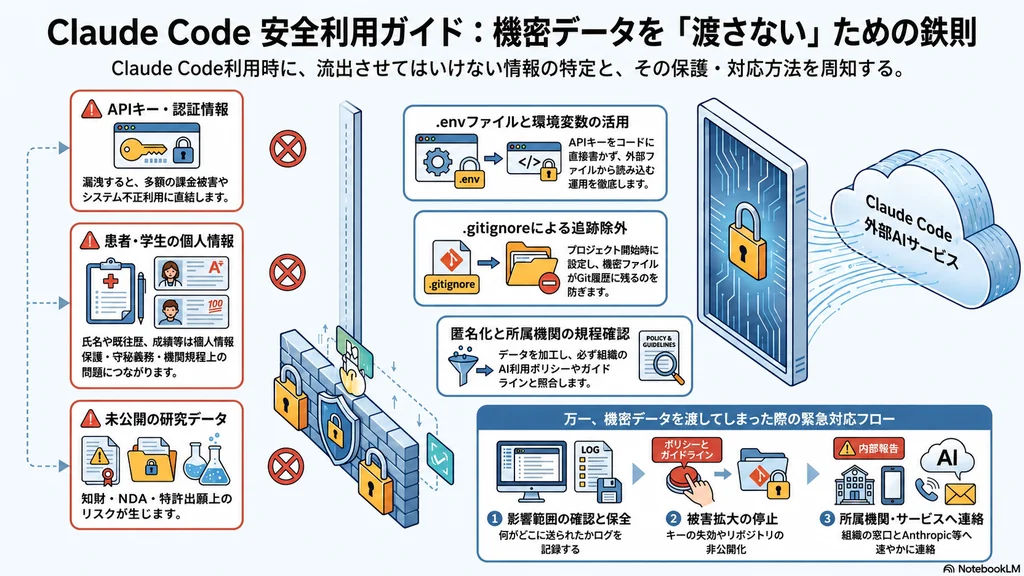
Claude Codeに渡してはいけない4種類のデータ
研究・医療・教育の現場で、特に注意したい4つのカテゴリを順番に整理します。
1. APIキー・認証情報
APIキー、アクセストークン、SSH秘密鍵、データベース接続文字列、SaaSサービスのパスワードなど、第三者にあなたとして操作を許してしまう類の情報です。一度漏れると、課金被害(数万円〜数百万円規模の事例が報告されています)、データ持ち出し、所属機関のシステム不正利用などにつながります。
具体的に避けるべき行為は次のとおりです。コードに直接api_key = "sk-..."のように書く、プロンプトに「このAPIキーを使って…」と貼り付ける、.envファイルをそのままGitにコミットする、スクリーンショットや画面共有でAPIキーを映す、メールやSlackでAPIキーを送る、といった操作はすべて避けてください。
2. 患者情報・診療データ
氏名、生年月日、保険情報、病名、既往歴、服薬情報、検査結果、画像データ、処方箋、SOAP記録、薬歴、トレーシングレポートなど、医療法や個人情報保護法上の「要配慮個人情報」に該当する情報群です。匿名化前のデータは、Claude Codeに開かせない・読み込ませない・要約させないという線引きを徹底します。
これらの情報の漏えいは、守秘義務違反として、行政上・民事上・場合によっては刑事上の責任につながる可能性があります。「電子カルテのスクリーンショットを要約してほしい」「院内システムから出力した患者リストを整形してほしい」というよくある依頼は、その時点で線を越えています。具体的な責任の有無や程度は、事案の内容や所属機関のインシデント対応窓口・法務担当の判断に依存するため、迷ったときはすぐに相談する流れにしておくのが安全です。
3. 学生情報・教育データ
学籍番号、氏名、所属、連絡先、成績、出席状況、レポート原本、個別指導記録、健康情報などです。教育機関の個人情報保護方針に従う必要があり、学生本人の事前同意、シラバス・学生通知でのAI利用範囲の明示が前提になります。
レポートの自動評価、成績一覧の要約、個別指導記録の整理といったタスクをAIに任せたくなる場面は多いですが、原本をそのまま渡す前に、学籍番号と氏名の切り離し、評価コメントの抽象化、機関規程との照合をかける癖をつけてください。
4. 未公開の研究データ・研究機密
未発表の実験データ、解析コード、共同研究先とのNDA下の情報、特許出願前の発明内容、化合物構造(SMILES、合成ルート)、競争的資金の申請書下書き、査読中の論文原稿などです。これらを外部AIサービスに送信すると、ただちに法的に「公知」と扱われるとは限りませんが、社内・所属機関で守ってきた秘密管理性が損なわれる可能性、共同研究先とのNDA違反のおそれ、特許出願や共同研究契約上のリスクが現実的に生じます。最終的な評価は、知財・法務部門と相談したうえで個別に判断する必要があります。
とくに、生成AIに「論文原稿を校正してほしい」と渡す行為は、査読中の論文では学術倫理上の問題になり得ます。共著者・所属機関・資金提供元との合意を確認したうえでなければ、未公開原稿は外部AIに渡さないのが安全側の運用です。
APIキーを守る:環境変数と.envファイル
APIキーを守る基本は、「コードにもプロンプトにも書かない」「環境変数として扱う」「Gitに含めない」の3点です。Pythonユーザーになじみのある運用としては、.envファイルに書いてpython-dotenvなどで読み込む方法が定着しています。
最小例を示します。プロジェクトのフォルダに.envを作り、次のように書きます。
ANTHROPIC_API_KEY=sk-ant-xxxxxxxxxxxx
OPENAI_API_KEY=sk-xxxxxxxxxxxxPythonコードからは、os.environ経由で参照します。
import os
from dotenv import load_dotenv
load_dotenv()
api_key = os.environ["ANTHROPIC_API_KEY"]このように書いておけば、コード本体にはAPIキーの文字列は一切現れません。Claude Codeにコードを読ませる場面でも、.envファイルさえ追跡対象から外しておけば、AIにキーを渡してしまう事故を構造的に防げます。
所属機関がAWS Secrets Manager、Azure Key Vault、Google Secret Managerのようなシークレットマネージャを提供している場合は、.envよりもそちらを優先するのが本筋です。とくにチーム運用や本番運用では、ローテーション(一定期間ごとにキーを発行し直す運用)が前提になります。
.gitignoreを最初に整える
機密ファイルがGitリポジトリに紛れ込む事故は、Claude Code以前のレベルでも頻繁に起こります。プロジェクトを始めるときに、.gitignoreを最初に整えてしまうのが、もっとも効果の高い予防策です。
最低限入れておきたい行を、最小構成で示します。
# 機密情報
.env
.env.*
*.key
*.pem
secrets/
credentials.json
# Python
__pycache__/
*.py[cod]
.venv/
venv/
# OS / IDE
.DS_Store
Thumbs.db
.vscode/
.idea/
# データ(内容に応じて、フォルダ単位で実データだけを除外する例)
data/raw/
data/private/データ周りで気をつけたいのは、*.csvや*.xlsxを拡張子で一律に除外してしまうと、教材用のサンプルデータや公開可能な架空データまでGit管理から外れてしまう点です。実データはdata/raw/やdata/private/のような「実データ専用フォルダ」にまとめて除外し、公開してよい架空データ・サンプルデータはdata/samples/のように別フォルダで管理して、これは追跡対象に残す、という設計が現実的です。フォルダ単位で線を引くことで、「うっかり実データをgit addしてしまう」事故も防ぎやすくなります。
一度.envをコミットしてしまうと、その後の履歴をたどれば誰でもキーを取り出せます。「履歴から消した」と思っても、リモートにすでにプッシュされていれば、漏えいは成立しています。コミット前にgit statusとgit diffで目視確認し、コミット後でもgit log -pで機密ファイルが含まれていないかを定期的に見直す習慣をつけます。
自動チェックとしては、git-secretsやgitleaksといったツールでコミット前にAPIキー混入を検出する仕組みや、GitHubの「Push Protection」(シークレットスキャン)を活用する方法があります。Push Protectionは2024年2月から、GitHub上の公開リポジトリで既定有効になっています。さらに、Anthropicは2024年8月にGitHubのsecret scanning partnerに参加しており、公開リポジトリでAnthropicのトークンが検出されると、GitHubがAnthropicに通知し、Anthropic側で自動的にキー失効と利用者への通知が行われる仕組みになっています。Claude Codeに「.gitignoreを点検して、機密ファイルが入っていないか確認してほしい」と依頼するのも、有効な使い方です。
機密データを「どうしても扱う」ときの加工:匿名化と架空データ
研究・教育・医療の現場では、データ自体を扱わずに済むケースは少数派です。そこで現実的な選択肢になるのが、データの加工です。
- 匿名化・仮名化:直接識別子(氏名、ID、電話番号、メールアドレス、住所)を削除または置換する。患者は「患者A」「患者B」、学生は「学生1」「学生2」のように匿名IDに置き換える
- 間接識別子の組み合わせを点検:年齢・性別・所属・診療科・地域などの組み合わせで個人が特定できないかを確認する。医療データでは「k-匿名性」(同じ属性値を持つ人がk人以上いる状態)を意識する
- 架空データの生成:教材・サンプルコードの動作確認では、Faker(Python)などで架空の人名・住所・電話番号を生成し、実データの代わりに使う
- 機密度に応じたローカル完結処理:匿名化後でも外部送信に懸念がある場合は、ローカルLLMや所属機関の閉域環境(オンプレミスの推論基盤)を選択肢に入れる
「匿名化したつもり」が一番危ない、というのが運用上の鉄則です。直接識別子を削っても、間接識別子の組み合わせから個人が特定できる事例は数多く報告されています。教材として渡す前に、所属機関のIRB(倫理審査委員会)や情報セキュリティ部門と相談する流れを、最初から組み込んでおくのが安全です。
所属機関の規程と国内法令との照合
個別の運用判断は、所属機関の規程と、関連する国内法令・ガイドラインとの整合性のなかで決まります。Claude Codeを業務に取り込むときは、次の3点を最初に確認します。
- 所属機関のAI利用ポリシー:生成AIに渡してよいデータの範囲、利用可能なサービス、ログ・監査の取り扱いを定めた内規。多くの医療機関・大学・企業で2024〜2026年にかけて整備が進んでいます
- 個人情報保護法・医療法・薬剤師法:日本国内では、個人情報保護法と医療系の業法が二重に効きます。外部AIサービスへの個人情報送信は「第三者提供」または「委託」に該当し得るため、本人同意または規程に基づく取扱いが前提になります
- いわゆる「三省二ガイドライン」:医療情報の取扱い・委託・クラウド利用に関する日本の主要な行政ガイドラインで、次の2つの総称です。①厚生労働省「医療情報システムの安全管理に関するガイドライン」(執筆時点では第6.0版、2023年5月公表)、②経済産業省・総務省「医療情報を取り扱う情報システム・サービスの提供事業者における安全管理ガイドライン」(執筆時点では第2.0版、2025年3月改定)。外部AIへの患者情報送信は、原則として厳格な管理下でのみ許容されます
研究データについては、内閣府・関係府省の方針(「公的資金による研究データの管理・利活用に関する基本的な考え方」(令和3年4月27日 統合イノベーション戦略推進会議決定)、「大学における研究データポリシー策定のためのガイドライン」など)や、所属機関の研究データポリシー、研究倫理委員会の承認範囲を併せて確認します。海外との共同研究では、GDPR(EU)、HIPAA(米国)などの域外規制が関係する場合があります。
もし渡してしまったときの初動
どれだけ気をつけても、事故は起こり得ます。万一APIキー・個人情報・研究機密をClaude Code経由で外部に送ってしまった場合、初動の順序を決めておくと被害を最小化できます。
- 影響範囲の確認:何が、どの時点で、どこに送られたかを記録する。スクリーンショット、コマンド履歴、メッセージログを保全
- 被害拡大の停止:APIキーであれば即時失効・再発行、リポジトリであれば一時的に非公開化、共有リンクであれば取り消し
- 所属機関への報告:個人情報・患者情報・研究機密が関係する場合は、所属機関のインシデント窓口・情報セキュリティ部門・倫理委員会へ速やかに連絡
- サービス側への連絡:Anthropic、GitHub、利用クラウド事業者のサポート窓口に状況を伝え、ログ削除や調査を依頼
- 再発防止策の整理:原因(プロンプト、フォルダ起動位置、
.gitignore漏れ等)を特定し、設定・運用ルール・チェックリストを更新
「自分が悪い」と隠してしまうのが、いちばん被害を広げます。早期報告のほうが、結果として組織にとっても個人にとっても被害を抑えられるのが原則です。
よくあるつまずきとその対処
第6回の段階で多くの方が遭遇する、代表的なつまずきを挙げておきます。
- 「これは個人情報ではない」と自己判断してしまう:氏名・住所・電話番号・メール以外にも、生年月日、職業、所属、Cookie ID、IPアドレス、画像・音声データなど多岐にわたります。「組み合わせで特定できるか」を基準に考えます
- 「匿名化したから安心」と思ってしまう:直接識別子を削っても、間接識別子の組み合わせで再識別される事例が複数報告されています。教材・公開資料に使う前に、第三者の目で点検します
- 「ローカルだから漏れない」と誤解する:Claude CodeはAnthropicのサービスに通信して動作するため、ローカルで起動していても、渡したファイルや会話は外部に送られます
.gitignoreを後回しにする:プロジェクトを作った瞬間に.gitignoreを整えるのが最善。.envをコミットしてからの取り消しは難しい
ファーマAIラボ的視点:薬剤師・研究者にとってのデータ保護リテラシー
薬剤師業務には、調剤録・薬歴・トレーシングレポートといった、極めて機微な情報を日常的に扱う場面があります。これらの情報は、もとから「外に出さない」という前提のもとに運用されてきました。Claude CodeをはじめとするAIエージェントは、便利さの代償として、この「外に出さない」前提を意識的に再確認することを求めてきます。
研究現場では、共同研究契約・NDA・倫理委員会の承認範囲という3重の枠組みのなかで、データを扱う約束ごとが決まっています。Claude Codeを研究フローに取り込むときは、新しい技術導入というよりも、既存の契約・規程・倫理審査の延長線上で「この用途はカバーされているか」「追加申請が必要か」を確認するつもりで臨むのが安全です。
AIを使いこなす力は、技術的なスキルだけでなく、「何を渡さないかを設計する力」と表裏一体です。本記事の内容は、薬剤師・研究者としての専門性と矛盾するものではなく、その延長線上にあるリテラシーとして捉えていただければと思います。
第6回のまとめ:「渡さない」を最初に決め、規程との照合で運用に乗せる
本記事では、Claude Codeを安全に使うためのデータ保護を扱いました。要点は次のとおりです。
- 権限管理(第5回)に加えて、「そもそも渡さない」設計を最初に置く
- 渡してはいけない代表的な4種類:APIキー、患者情報、学生情報、未公開研究データ
- APIキーは環境変数・
.env・シークレットマネージャで管理し、コードやプロンプトに書かない .gitignoreを最初に整え、機密ファイルがGitに紛れ込まないようにする- 機密データを扱うときは、匿名化・架空データ・ローカル完結処理で加工する
- 所属機関のAI利用ポリシー、個人情報保護法、医療法、三省二ガイドライン、研究倫理指針との照合を運用に組み込む
- 万一の事故時は、影響範囲確認 → 被害停止 → 機関報告 → サービス連絡 → 再発防止、の順で動く
権限管理とデータ保護の二段構えで、第2章「事前準備と安全」は一区切りです。第3章では、いよいよClaude Codeとの実際のやり取り(プロンプト設計、コード読解、デバッグ)に進みます。
第2章のまとめ:ここまでの到達点
第4回から本記事までで、Claude Codeを安心して使い始めるための土台が揃いました。
- 第4回:フォルダ・ターミナル・Gitの基礎(コードの外側の3つの基礎概念)
- 第5回:権限モードと
settings.json(AIにどこまで任せるかを設計する枠組み) - 第6回:データ保護と規程との照合(そもそも何を渡さないかを最初に決める)
これらは地味な作業に見えますが、Claude Codeを業務・研究・教育で長く使うための足場です。土台が整えば、次章以降の「指示の出し方」「コード読解」「デバッグ」「リファクタリング」といった話題に、安心して踏み込めます。
次回予告
第7回は「Claude Codeに良い指示を出す方法」です。第3章(基本操作)の最初の回として、プロンプトを「作業依頼書」として設計する考え方を扱います。目的・前提・入力・出力形式・制約という5つの軸でプロンプトを組み立て、反復改善(指示→出力→評価→修正指示)のリズムを身につけるのがゴールです。
公式ドキュメント参照のリマインド
Claude Codeのデータ取扱方針、利用規約、エンタープライズ向けのデータ保護機能は短期間で更新されます。本記事の内容は2026年6月時点の情報を基に執筆していますが、業務・研究での導入前に、必ずAnthropic公式ドキュメント(https://code.claude.com/docs)とデータ取扱に関するページで最新の方針を確認してください。日本国内法令や所属機関の規程は、Anthropic側の方針とは別の軸として常に併走することを意識してください。
参考文献・関連リンク
- Anthropic公式:Claude Code Docs(
https://code.claude.com/docs) - Anthropic公式:Claude Code 製品ページ(
https://claude.com/product/claude-code) - 個人情報保護委員会(
https://www.ppc.go.jp/) - 厚生労働省「医療情報システムの安全管理に関するガイドライン」(執筆時点で第6.0版、2023年5月公表)
- 経済産業省・総務省「医療情報を取り扱う情報システム・サービスの提供事業者における安全管理ガイドライン」(執筆時点で第2.0版、2025年3月改定)
- 内閣府・統合イノベーション戦略推進会議「公的資金による研究データの管理・利活用に関する基本的な考え方」(令和3年4月27日決定)
- 内閣府「大学における研究データポリシー策定のためのガイドライン」
- Anthropic is now a GitHub secret scanning partner(GitHub Changelog, 2024-08-20)
- 本シリーズ第5回:Claude Codeを安全に使うための権限管理入門
- 本シリーズ第7回(次回):Claude Codeに良い指示を出す方法
- 本シリーズの公式コンセプト:claude-code-python-blog-series-plan.md(ファーマAIラボ内部資料)
本記事の位置づけに関する注記
本記事は、Anthropicが公開しているClaude Code関連情報および日本国内の関連法令・ガイドラインを参考に、Python学習経験のある非エンジニア向けに筆者が独自に構成・解説したものです。AnthropicまたはClaude Codeの公式記事ではなく、また法的助言でもありません。仕様、料金、対応環境、利用条件、関係法令・ガイドラインは変更される可能性があるため、最新情報は公式ドキュメント・所管官庁・所属機関の規程をご確認ください。
制作ノート
本シリーズの記事およびサンプルコードは、Claude Code/Claude Opus 4.7を活用して執筆しています。AI生成情報については、公式ドキュメント・公的機関の公表資料等の一次情報で裏取りした上で掲載しています。読者の皆さまにおかれましても、AIを使って成果物を公開する際は、AI関与の透明化を推奨します。
免責事項
本記事は生成AIを活用して作成しています。内容については十分に精査しておりますが、誤りが含まれる可能性があります。また、Claude Codeおよび関連サービスの仕様・料金、ならびに関連法令・ガイドラインは変更される場合があります。最新かつ正確な情報は必ず公式ドキュメントおよび所管官庁・所属機関の規程をご確認ください。本記事は法的助言ではありません。お気づきの点がございましたら、コメントにてご指摘いただけますと幸いです。なお、本記事の内容に基づいて生じたいかなる損害についても、当サイトは責任を負いかねます。
Amazonでこの関連書籍「ストーリーで覚えるClaude Code開発ガイド: 物語で学ぶAI駆動開発」を見る