
1. はじめに:なぜXGBoostは記述子QSARの「定番」なのか
AI創薬の現場では、深層学習やグラフニューラルネットワークが注目を集めています。しかし、分子記述子(分子の構造を数値化した特徴量)を入力としたQSAR(Quantitative Structure-Activity Relationship:定量的構造活性相関)モデリングにおいては、いまもXGBoostが代表的な手法の一つであり、「まず比較対象に入れるべき強力なベースライン」として広く利用されています。
本記事では、XGBoostがQSARで高く評価される技術的な理由を、勾配ブースティングの仕組みから、ADMET予測などの実績、SHAPによる解釈、ハイパーパラメータ調整のポイントまで、step-by-stepで解説します。なお、XGBoostはあくまで予測を支援するツールであり、実験的検証や専門家の判断を置き換えるものではない点を最初におさえておきましょう。
2. XGBoostとは?勾配ブースティング決定木の進化形
XGBoost(eXtreme Gradient Boosting)は、2016年にTianqi ChenとCarlos Guestrinが論文「XGBoost: A Scalable Tree Boosting System」(KDD 2016)で発表した、勾配ブースティング決定木(Gradient Boosting Decision Tree:GBDT)の実装です。多くの機械学習コンペティションで好成績を収め、いまでは表形式データの定番手法となっています。
2.1 勾配ブースティングの仕組み
勾配ブースティングは、決定木という「弱い学習器」を逐次的に積み重ねるアンサンブル学習の一種です。前のモデルが間違えた部分(予測誤差)を、次に追加する決定木が重点的に学習することで、全体として強力な予測モデルを組み立てます。
多数の決定木を独立かつ並列に学習させるランダムフォレスト(Random Forest)に対し、XGBoostは誤差を逐次的に修正していく点が異なります。この「前のモデルの弱点を次が補う」設計が、高い予測精度につながります。
2.2 XGBoost独自の最適化技術
XGBoostは、従来のGBDTに対していくつかの工夫を加えています。代表的なものは次の通りです。
- 正則化項:L1・L2正則化を損失関数に組み込み、過学習(学習データに適合しすぎて未知データで精度が落ちる現象)を抑制します
- 並列処理:分割点の探索を並列化し、単一マシンでも高速に学習できます
- 欠損値への対応:欠損値があっても、その振り分け方向をデータから自動で学習します
- 疎データ対応(sparsity-aware):多くの値が0であるような疎な特徴量を効率的に扱えます
論文では、この疎データ対応アルゴリズムと、近似的な分割点探索を行う「weighted quantile sketch」が主要な貢献として挙げられています。これらが、後述するフィンガープリントとの相性の良さを支えています。
3. 分子記述子・フィンガープリントとの高い相性
QSARでは、分子の構造を数値化した分子記述子を入力に使います。分子量や水素結合ドナー数といった物理化学的記述子から、部分構造の有無をビット列(0と1の並び)で表すフィンガープリントまで、種類はさまざまです。
なかでも広く使われるのが、Morganフィンガープリント(ECFP:Extended Connectivity Fingerprints)です。これは分子内の部分構造をハッシュ化し、数千〜数万ビットのうち少数だけが1になる「疎なビット列」として分子を表現します。
前述のとおり、XGBoostは疎な特徴量を効率的に処理できる設計になっているため、ECFPのようなフィンガープリントとの相性が非常に良いのです。物理化学的記述子とフィンガープリントを組み合わせた「ハイブリッド記述子」を入力にできる柔軟さも、実務で重宝されています。
4. QSARでの実績とベンチマーク
4.1 ADMET予測での高い性能
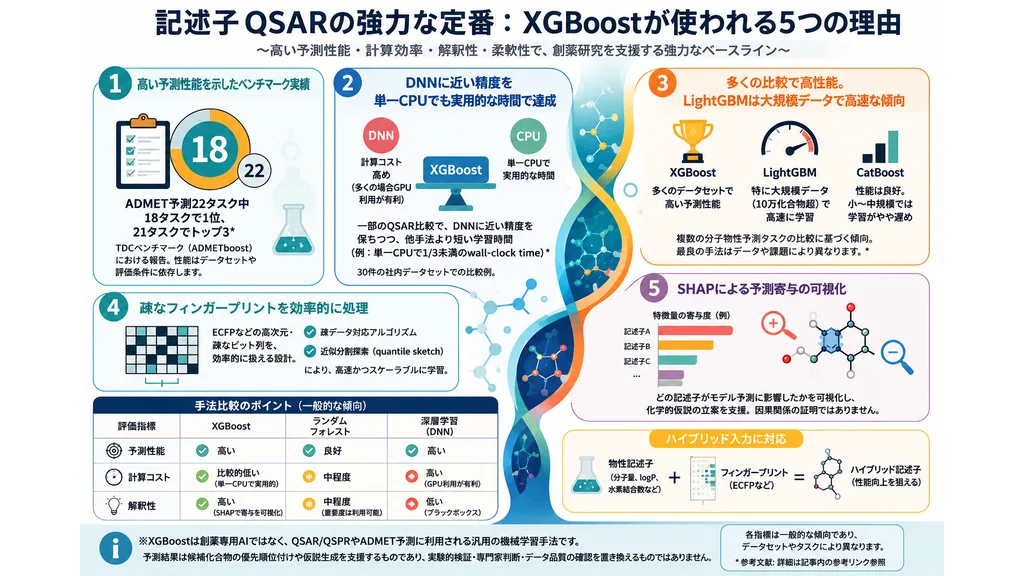
Tianらの研究「Accurate ADMET Prediction with XGBoost」(arXiv:2204.07532、2022年)では、フィンガープリントと記述子を組み合わせたXGBoostモデルを、創薬向けベンチマーク集Therapeutics Data Commons(TDC)のADMET課題で評価しています。
その結果、薬物の吸収・分布・代謝・排泄・毒性(ADMET)に関する22タスクのうち、18タスクで1位、21タスクでトップ3という成績を収めました。学習済みモデルはWebサーバー「ADMETboost」として公開されており、その内容は査読誌Journal of Molecular Modeling(2022年、28巻408)にも報告されています。
4.2 ランダムフォレスト・深層学習との比較
Sheridanらの研究(Journal of Chemical Information and Modeling、2016年)では、30の社内データセットを用いてXGBoostをランダムフォレストおよび深層ニューラルネットワーク(DNN)と比較しました。報告された傾向は次の通りです。
- 予測精度:平均してランダムフォレストより優れ、DNNとほぼ同等
- 計算時間:単一CPU上で、ランダムフォレストやDNNの3分の1未満の実時間(wall-clock time)で完了
クラスタやGPUを前提とする手法に対し、単一CPUで実用的な時間に収まる点は、計算資源が限られる現場で大きな利点になります。
4.3 LightGBM・CatBoostとの使い分け
Boldiniらの研究(Journal of Cheminformatics、2023年)では、XGBoost・LightGBM・CatBoostという3つの勾配ブースティング実装を、多数の分子物性予測タスクで比較しました。要点は次の通りです。
- XGBoost:予測性能が最も高く、おおむね約5%の優位。ただし大規模データでは学習に時間がかかる
- LightGBM:学習が最も高速で、特に10万化合物を超える大規模データで効率的
- CatBoost:性能は良好だが、小〜中規模では学習が比較的遅い
高い予測精度を重視する場面ではXGBoostが有力で、大規模データで学習速度を重視するならLightGBM、という使い分けが一つの目安になります。ただし、どの手法が最良かはデータセットの規模・化学空間・評価分割・クラス不均衡・ハイパーパラメータ調整に左右されるため、自分のデータでの比較検証が前提となります。
5. 解釈可能性:SHAPとの組み合わせ
創薬では「なぜそう予測したのか」を理解することが重要です。XGBoostは、予測への各特徴量の寄与を算出するSHAP(SHapley Additive exPlanations)と組み合わせやすく、次のような洞察が得られます。
- 特徴量重要度:どの記述子が予測に強く寄与しているか
- 個別予測の解釈:特定の化合物の予測に各記述子がどう影響したか
- 相互作用の把握:記述子どうしの組み合わせ効果の確認
これにより、XGBoostは単なる予測器にとどまらず、活性の要因に関する仮説を導く道具としても活用できます。ただしSHAP値は相関に基づく説明であり、因果関係そのものを保証するものではない点には注意が必要です。
6. 実践事例:抗がん性小分子の予測(XGBPred-ACSM)
XGBPred-ACSM(MDPI Pharmaceuticals、2026年)は、ハイブリッド記述子を用いたXGBoostフレームワークの一例です。実験的に検証された3,600個の抗がん性小分子(IC50値を持つ化合物)を対象に、MordredとPaDELで2D記述子とフィンガープリントを生成し、XGBoostを含む6つのアルゴリズムを比較しています。
同論文では、2D記述子単独やフィンガープリント単独よりも、両者を統合したハイブリッド記述子のほうが予測性能が高く、最良のXGBoostモデルはテストセットでAUC0.88・正解率79.11%(訓練セットではAUC0.90・正解率82.05%)と報告されています。さらにSHAP分析により、予測に寄与する分子の決定因子を特定しています。あくまで単一研究の報告値であり、適用範囲や検証条件に依存する点は踏まえて読む必要があります。
7. ハイパーパラメータ調整のポイント
XGBoostは調整可能なパラメータが多いものの、まずは以下に絞ると効率的です。
- learning_rate(学習率):0.01〜0.3 程度。小さいほど慎重に学習する
- max_depth(木の深さ):3〜10 程度。大きいほど複雑になり過学習しやすい
- subsample / colsample_bytree(サンプリング比率):0.6〜1.0。過学習の抑制に有効
- scale_pos_weight:活性・不活性が偏った不均衡データで、少数クラスの重みを調整
計算資源が限られる場合は、まず学習率と不均衡データ対策(scale_pos_weight)から着手し、その後に木の深さやサンプリング比率を詰めていくとよいでしょう。検証用データを分け、未知データへの汎化性能で評価することが欠かせません。
8. まとめ:記述子QSARの代表的な手法の一つ
XGBoostが記述子QSARで「強い定番モデル」とされる理由は、(1)報告例ではランダムフォレストを上回りDNNに匹敵した予測精度、(2)単一CPUで完結する計算効率、(3)SHAPと組み合わせた解釈可能性、(4)フィンガープリントやハイブリッド記述子に対応する汎用性、そして(5)ADMET予測をはじめとする豊富な実績、の5点に集約できます。これらは「事実上の標準」と断ずるものではなく、まず比較対象に入れるべき有力なベースラインとしての評価と理解するのが適切です。
実際、最良の手法はデータ規模や課題によって変わります。大規模データではLightGBM、3D構造や複雑な関係性を扱う場面ではグラフニューラルネットワークが適することもあります。XGBoostを「まず試す強力なベースライン」と位置づけ、自分のデータで小さく比較検証することをおすすめします。そして、こうした予測はあくまで候補化合物の優先順位付けや仮説生成を支援するものであり、実験的検証・専門家の判断・データ品質の確認を置き換えるものではない点を、最後に改めて強調しておきます。
参考リンク
- XGBoost 公式ドキュメント:https://xgboost.readthedocs.io/
- Chen & Guestrin「XGBoost: A Scalable Tree Boosting System」(KDD 2016 / arXiv:1603.02754):https://arxiv.org/abs/1603.02754
- Tian et al.「Accurate ADMET Prediction with XGBoost」(arXiv:2204.07532):https://arxiv.org/abs/2204.07532
- Tian et al.「ADMETboost: a web server for accurate ADMET prediction」(査読誌 J. Mol. Model. 28:408, 2022):https://link.springer.com/article/10.1007/s00894-022-05373-8
- Sheridan et al.「Extreme Gradient Boosting as a Method for QSAR」(JCIM 2016):https://pubs.acs.org/doi/10.1021/acs.jcim.6b00591
- Boldini et al.「Practical guidelines for the use of gradient boosting for molecular property prediction」(J. Cheminform. 2023):https://jcheminf.biomedcentral.com/articles/10.1186/s13321-023-00743-7
- XGBPred-ACSM(MDPI Pharmaceuticals 2026):https://www.mdpi.com/1424-8247/19/4/635
- SHAP ドキュメント:https://shap.readthedocs.io/
免責事項
本記事は、XGBoostおよびQSAR・AI創薬に関する情報提供を目的として作成されたものです。記事の内容は、公開時点で入手可能な文献・情報に基づいていますが、技術の進歩や新たな知見により、情報が変更される場合があります。記事に記載されたソフトウェアの使用結果や、それに基づく研究成果について、筆者および本ブログは一切の責任を負わないものとします。実際の創薬研究や臨床応用にあたっては、必ず最新の文献・公式ドキュメントを確認し、専門家の助言を得てください。
本記事は生成AIを活用して作成しています。内容については十分に精査しておりますが、誤りが含まれる可能性があります。お気づきの点がございましたら、コメントにてご指摘いただけますと幸いです。なお、本記事の内容に基づいて生じたいかなる損害についても、当サイトは責任を負いかねます。
Amazon関連書籍 Amazonでこの関連書籍「機械学習のエッセンス -実装しながら学ぶPython,数学,アルゴリズム-」を見る
関連YouTubeリンク