
1. はじめに:なぜ今、創薬研究者がPyTorchを学ぶべきなのか
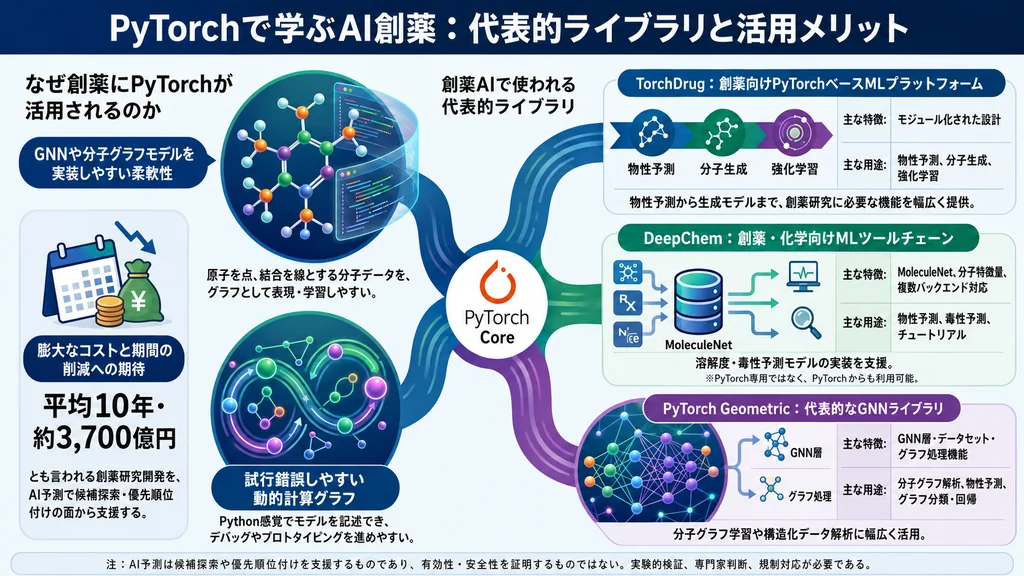
新しい医薬品を1つ世に送り出すには、平均で約10年の歳月と25億ドル(約3,700億円)もの費用がかかると言われています。標的探索、候補化合物探索、物性予測、ADMET予測といった一部の工程を効率化する技術として、いま機械学習・深層学習(ディープラーニング)への期待が高まっています。
その深層学習を支える土台として、創薬AI研究でも広く利用されているのが「PyTorch(パイトーチ)」です。ここで一点おさえておきたいのは、PyTorchは創薬専用のツールではなく、ニューラルネットワークやGNN、Transformer、生成モデルなどを実装するための汎用的な深層学習フレームワーク(開発基盤)だということです。つまり「AI創薬ツール」というより「AI創薬で利用される計算・解析の支援基盤」と捉えるのが正確です。本記事では、PyTorchの基礎から、TorchDrugやDeepChemといった関連ライブラリ、グラフニューラルネットワーク(GNN)まで、AI創薬の基盤技術をstep-by-stepでわかりやすく解説します。
2. PyTorchとは?深層学習の基盤フレームワーク
PyTorchは、Meta社(旧Facebook)のAI研究部門に由来するオープンソースの深層学習フレームワーク(AIモデルを構築するための開発基盤)です。現在はPyTorch Foundationを中心とするコミュニティのもとで開発・運営されています。「研究のプロトタイピングから本番環境への展開まで」を加速することを掲げ、柔軟性と使いやすさを両立させた設計が大きな特徴です。
PyTorchが世界中の研究者に支持される理由は、主に次の4点に集約されます。
- 動的計算グラフ:プログラムを実行しながらネットワーク構造を組み立てられるため、Pythonの感覚で直感的に書け、エラーの原因(デバッグ)も追いやすい
- GPUによる高速化:CUDA対応のGPUを使い、学習と推論を高速に実行できる
- 自動微分(Autograd):勾配計算(学習に必要な微分)を自動で行い、誤差逆伝播を簡単に実装できる
- 豊富なエコシステム:画像・自然言語・創薬など、分野ごとに特化したライブラリが充実している
3. なぜ創薬にPyTorchが選ばれるのか
創薬分野でPyTorchが特に重宝される最大の理由は、分子データの「非格子構造」を扱いやすい点にあります。分子は、原子を点(ノード)、結合を線(エッジ)とする「グラフ構造」で自然に表現できますが、画像のような規則正しい格子状のデータとは性質が異なります。PyTorchはこうした不規則なデータ構造にも柔軟に対応できます。
加えて、最新の深層学習技術がいち早く実装される活発な研究コミュニティの存在、NumPyやRDKit(化学情報を扱うライブラリ)など科学計算ツールとの相性の良さも、創薬研究者にとって大きな魅力となっています。具体的な応用領域は、薬物標的の同定、薬物-標的相互作用の予測、新規分子を生み出すデ・ノボ設計、毒性予測、ADMET(吸収・分布・代謝・排泄・毒性)予測など多岐にわたります。
4. PyTorch創薬エコシステム:押さえるべき3大ライブラリ
PyTorchを中心とした深層学習エコシステムのなかで、創薬・化学に特化した強力なライブラリ群が育っています。ここでは代表的な3つを紹介します(このうちDeepChemはPyTorch専用ではなく複数のバックエンドに対応しますが、PyTorchからも利用できるため本章でまとめて取り上げます)。
4.1 TorchDrug:創薬特化の統合プラットフォーム
TorchDrugは、PyTorchをベースとした創薬向けの機械学習プラットフォームです(論文発表は2022年)。グラフ機械学習、深層生成モデル、強化学習までを幅広く網羅し、創薬の専門知識が少ない実務家でも扱いやすいよう設計されているのが特徴です。データ構造・データセット・レイヤー・モデル・タスクといった階層構造で部品が整理されており、目的に応じて柔軟に組み合わせられます。
以下は、毒性予測タスク(ClinToxデータセット)をわずか数行で実装する例です。
from torchdrug import datasets, models, tasks, core
import torch
# データセットの読み込み
dataset = datasets.ClinTox(path="./", verbose=1)
# Graph Isomorphism Network (GIN) の定義
model = models.GIN(input_dim=dataset.node_feature_dim,
hidden_dims=[256, 256, 256, 256])
# 物性(毒性)予測タスクの定義
task = tasks.PropertyPrediction(model, task=dataset.tasks, criterion="bce")
# 学習エンジンの設定と実行
optimizer = torch.optim.Adam(task.parameters(), lr=1e-3)
solver = core.Engine(task, dataset, dataset, dataset, optimizer, gpus=[0])
solver.train(num_epoch=100)
solver.evaluate("valid")※上記はチュートリアル用に簡略化したコードで、訓練・検証・テストに同じデータセットを渡しています。実際の性能評価では、データを訓練用・検証用・テスト用に適切に分割(split)し、未知データに対する汎化性能を測る必要があります。
4.2 DeepChem:創薬を民主化するツールチェーン
DeepChemは「創薬における深層学習の民主化」を掲げるオープンソースライブラリです。分子特性予測や毒性予測などのタスクを簡単に実装でき、ECFP(分子の特徴を数値化する指紋情報)や、MoleculeNetという豊富なデータセット群とも統合されています。初心者でもチュートリアルを通じてAI創薬に取り組める点が強みです。なお、DeepChemはPyTorch専用ではなく、TensorFlowやJAXなど複数のバックエンドに対応した創薬・化学向けライブラリで、PyTorchからも利用できます。
応用例として水溶解度の予測が挙げられます。水溶解度は経口吸収性や製剤設計に関わる重要な物性の一つです。開発初期に溶解度を予測することで、物性面のリスクを事前に見積もり、候補化合物の優先順位付けに役立てることができます。ただし、溶解度は薬効や開発成功の可否を単独で判断できる指標ではない点には注意が必要です。
4.3 PyTorch Geometric:分子グラフ学習の強力な拡張
PyTorch Geometric(PyG)は、グラフニューラルネットワーク(GNN)を簡単に記述・学習できるよう設計されたライブラリです。GCN・GAT・GraphSAGEといった代表的なGNN層や、QM9のような標準データセットをすぐに利用できます。創薬に限らず、構造化データ全般を扱う研究で広く使われているツールです。
5. 創薬で活躍する主要GNNモデル
分子をグラフとして扱う際に中心的役割を果たすのが、グラフニューラルネットワーク(GNN)です。代表的な3つのモデルを押さえておきましょう。
- GCN(Graph Convolutional Network):隣り合う原子の特徴を集約し、各原子の文脈情報を捉える、最も基盤的なモデル
- GAT(Graph Attention Network):「注意機構(Attention)」を導入し、どの隣接原子をどれだけ重視するかを学習。重要な相互作用を捉える能力が高い
- GIN(Graph Isomorphism Network):グラフの違いを見分ける理論(Weisfeiler-Lehmanテスト)に基づき、表現力の高い分子表現を学習。TorchDrugのチュートリアルや実装例で利用される代表的なエンコーダーの一つ
6. 最新動向:エコシステムはさらに拡大中
PyTorchを核とした創薬エコシステムは、いまも急速に進化を続けています。注目すべき動きを3つ紹介します。
NVIDIA BioNeMo Frameworkは、計算創薬・デジタルバイオロジー向けのプログラミングツール、ライブラリ、モデル群からなるフレームワークです。BioNeMo Frameworkに関する論文は2024年11月に公開されました。PyTorchをベースに、タンパク質言語モデル(ESM-2)の学習・推論や、単一細胞データ向けのPyTorch互換データ処理(BioNeMo-SCDL)など、生体分子AIモデルの開発をGPU上で効率化する機能を提供します。製薬大手Amgenでの活用事例も報告されています。
また、タンパク質構造予測で大きな注目を集めたAlphaFold 2には、PyTorchベースの学習可能な再実装であるOpenFoldも存在します。OpenFoldは構造予測研究や大規模な構造解析ワークフローに有用です。ただし、AlphaFold系モデルの主目的はあくまでタンパク質構造の予測であり、リガンド(薬物)の結合様式や結合親和性、薬効を直接保証するものではありません。構造ベース創薬への応用にあたっては、ドッキングや分子動力学シミュレーション、そして実験的検証と組み合わせて解釈する必要があります。さらに、実験管理を効率化するPyTorch LightningとDeepChemの統合も2025年のGoogle Summer of Codeで採択されるなど、開発環境の整備も着実に進んでいます。
7. 学習リソースとおすすめデータセット
これからPyTorchで創薬AIを学ぶ方には、次の順序がおすすめです。まずPyTorch公式チュートリアル(日本語版あり)で基礎を固め、RDKitで分子構造の扱いに慣れ、PyTorch GeometricでGNN入門、最後にTorchDrugやDeepChemのチュートリアルで創薬応用に進む、という流れです。
実践でよく使われる主要データセットも押さえておきましょう。量子化学特性を持つ約13万分子のQM9(分子物性予測)、FDA承認・臨床毒性データのClinTox(毒性予測)、複数タスクを束ねたMoleculeNet、薬物-タンパク質の結合データBindingDBなどが代表的です。
8. まとめ:PyTorchはAI創薬研究で広く使われる深層学習基盤
PyTorchは、GNN・Transformer・生成モデルなどを柔軟に実装できる深層学習フレームワークであり、TorchDrug・DeepChem・PyTorch Geometricといった周辺ライブラリと組み合わせることで、分子物性予測、毒性予測、分子生成、薬物-標的相互作用予測など、幅広い創薬AI研究に活用できます。AI創薬を支える基盤の一つとして、その存在感は年々高まっています。
ただし、忘れてはならないのは、AIによる予測は候補化合物の優先順位付けや仮説生成を支援するものであり、実験的検証や専門家の判断、規制対応を置き換えるものではないという点です。予測精度は学習データ・評価方法・適用範囲に強く依存するため、結果を安全性や有効性の証明として扱うことはできません。また、PyTorchやTorchDrug、OpenFoldなどはオープンソースですが、商用利用や再配布、モデルの重み・データセットの扱いはライセンスごとに条件が異なるため、特に企業での利用を想定する場合は事前の確認が欠かせません。
こうした前提を理解したうえで活用すれば、PyTorchは創薬研究の強力な味方となります。まずは公式チュートリアルから、第一歩を踏み出してみてはいかがでしょうか。
参考リンク
- PyTorch 公式サイト:https://pytorch.org/
- TorchDrug 公式サイト:https://torchdrug.ai/
- TorchDrug 論文(arXiv:2202.08320):https://arxiv.org/abs/2202.08320
- DeepChem 公式サイト:https://deepchem.io/
- PyTorch Geometric ドキュメント:https://pytorch-geometric.readthedocs.io/
- NVIDIA BioNeMo Framework:https://github.com/NVIDIA/bionemo-framework
- PyTorch公式チュートリアル(日本語版):https://yutaroogawa.github.io/pytorch_tutorials_jp/
免責事項
本記事は、PyTorchおよびAI創薬に関する情報提供を目的として作成されたものです。記事の内容は、公開時点で入手可能な文献・情報に基づいていますが、技術の進歩や新たな知見により、情報が変更される場合があります。記事に記載されたソフトウェアの使用結果や、それに基づく研究成果について、筆者および本ブログは一切の責任を負わないものとします。実際の創薬研究や臨床応用にあたっては、必ず最新の文献・公式ドキュメントを確認し、専門家の助言を得てください。
本記事は生成AIを活用して作成しています。内容については十分に精査しておりますが、誤りが含まれる可能性があります。お気づきの点がございましたら、コメントにてご指摘いただけますと幸いです。なお、本記事の内容に基づいて生じたいかなる損害についても、当サイトは責任を負いかねます。