
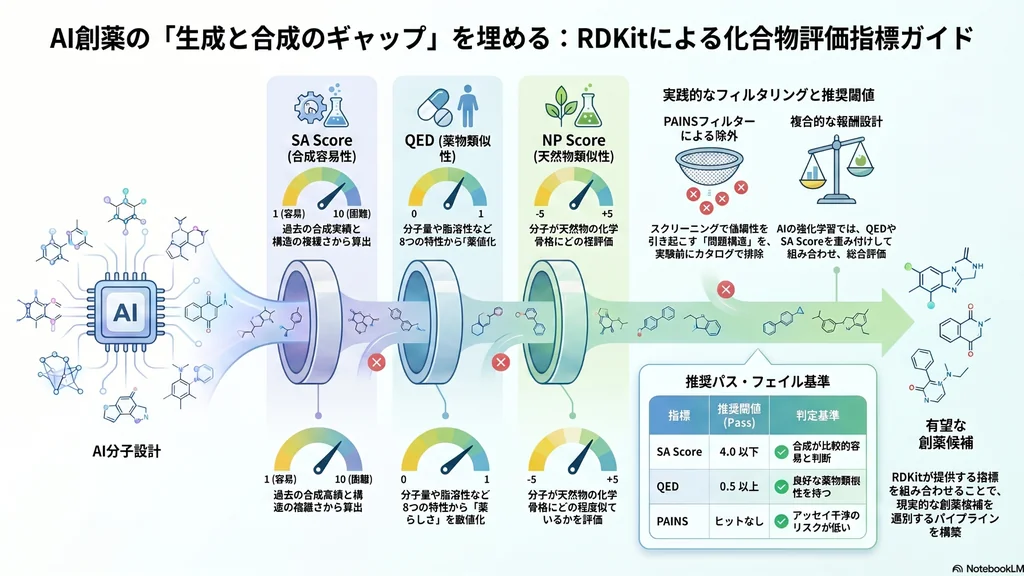
1.はじめに:AI創薬における「生成と合成のギャップ」
生成AIや強化学習による分子設計が一般化した今、新規化合物を膨大に生成すること自体は容易になりました。しかし、生成された分子の多くは合成困難であったり、薬物として現実的でない構造を含んでいたりするため、実用候補に絞り込むには定量的な評価指標が不可欠です。
この課題に対し、RDKit ContribはSA Score、NP Score、QEDなど、合成容易性・薬物類似性・天然物類似性を評価する一連の補助指標を提供しています。本記事では、これらの指標の理論的背景、実装方法、推奨閾値、そしてAI創薬パイプラインへの組み込み方を、医療関係者・創薬研究者向けに整理します。
2.RDKit Contribとは:コアRDKitとの違い
RDKit Contribは、オープンソースのケモインフォマティクスツールキットRDKitのコア機能には含まれていない、コミュニティ提供の追加モジュール群です。コアRDKitとは別に管理されている主な理由は、大規模なデータファイル(フラグメント辞書、訓練済みモデル等)を必要とするためです。
conda-forgeやPyPI経由でRDKitをインストールすると、Contribモジュール群もパッケージに同梱されます。Greg Landrum氏(RDKit主開発者)のブログでは、ContribモジュールはPython実装で提供され、AI創薬において補助指標として広く活用されている旨が解説されています。
3.SA Score(合成容易性スコア):理論と実装
3.1. 原論文と背景
SA Score(Synthetic Accessibility Score)は、Peter ErtlとAnsgar Schuffenhauer(当時Novartis Institutes for BioMedical Research)が2009年に発表した指標です。
- 論文タイトル:Estimation of synthetic accessibility score of drug-like molecules based on molecular complexity and fragment contributions
- 掲載誌:Journal of Cheminformatics, 2009, 1:8
- DOI:10.1186/1758-2946-1-8
スコアは1(合成が容易)から10(極めて困難)の範囲を取り、創薬候補化合物のフィルタリングに広く用いられています。
3.2. スコアの構成要素
SA Scoreは2つの主要なコンポーネントから構成されます。
- Fragment Score(フラグメントスコア):PubChemに含まれる約100万化合物から抽出されたフラグメントの出現頻度に基づき、過去の合成実績を数値化したもの
- Complexity Score(複雑性スコア):環構造の複雑性、立体化学、大員環ペナルティ、分子サイズなどから構成される構造複雑度の罰則項
3.3. 実装例
RDKit Contribを用いたSA Scoreの計算例は以下のとおりです。
from rdkit import Chem
from rdkit.Contrib.SA_Score import sascorer
mol = Chem.MolFromSmiles('CC(=O)OC1=CC=CC=C1C(=O)O') # アスピリン
score = sascorer.calculateScore(mol)
print(f"SA Score: {score:.2f}")conda経由のインストールでは、sys.pathにContribディレクトリを追加する必要があります。PyPI版ではfrom rdkit.Contrib.SA_Score import sascorerとして直接読み込めます。
4.QED(定量的薬物類似性推定)
4.1. 原論文と背景
QED(Quantitative Estimate of Drug-likeness)は、G. Richard BickertonとGaia V. Paoliniらが2012年に発表した「薬物の化学的美しさ(chemical beauty)」を定量化する指標です。
- 論文タイトル:Quantifying the chemical beauty of drugs
- 掲載誌:Nature Chemistry, 2012, 4:90-98
- DOI:10.1038/nchem.1243
QEDは0〜1のスコアを取り、1に近いほど経口薬として理想的な分子特性プロファイルを持つと評価されます。
評価される8つの分子特性
QEDは以下の8つの分子特性を統合します。
- 分子量(MW)
- 脂溶性(ALOGP)
- 水素結合アクセプター数(HBA)
- 水素結合ドナー数(HBD)
- 極性表面積(PSA)
- 回転可能結合数(ROTB)
- 芳香族環数(AROM)
- 構造アラート数(ALERTS)
各特性に対する「望ましさ関数(desirability function)」を経験的に定義し、それらの幾何平均を取ることで総合的な薬物類似性を1つのスコアに集約しています。
4.2. 実装例
from rdkit.Chem import QED
mol = Chem.MolFromSmiles('CC(=O)OC1=CC=CC=C1C(=O)O')
qed_score = QED.default(mol)
print(f"QED: {qed_score:.3f}")
# 各特性値の確認
properties = QED.properties(mol)
print(properties)QEDはRDKitコアに含まれているため、Contribを別途読み込む必要はありません。
5.NP Score(天然物類似性スコア)
NP Score(Natural Product-likeness Score)は、分子が天然物にどれだけ似ているかを定量化する指標です。スコア範囲は−5(天然物らしくない)〜+5(非常に天然物に似ている)で、ChEMBL 32の解析では分布は−4.1〜+4.1の範囲、中央値は約−1とされています。
天然物は進化的に選択された多様な化学骨格を持ち、創薬の重要な出発点となるため、生成分子のスクリーニングや天然物指向の分子設計で活用されます。
from rdkit.Contrib.NP_Score import npscorer
fscore = npscorer.readNPModel()
mol = Chem.MolFromSmiles('CC(=O)OC1=CC=CC=C1C(=O)O')
score = npscorer.scoreMol(mol, fscore)
print(f"NP Score: {score:.2f}")6.その他の重要な補助指標
6.1. Spacial Score(SPS/nSPS)
Spacial Score(SPS)は、分子の空間的複雑性を評価する比較的新しい指標で、sp3混成炭素割合、立体中心の存在、非芳香族環構造、重原子の近接性などから計算されます。分子サイズで正規化したnSPSを用いることで、異なるサイズの分子間で比較可能になります。
SPSは現在、ContribではなくコアRDKitのrdkit.Chem.SpacialScoreモジュールとして提供されています(RDKit 2024以降)。Contribに記載のある旧情報を見かけた場合は、現行の公式モジュールを参照してください。
6.2. Filter Catalogs:PAINS等の構造フィルター
RDKitには、アッセイ干渉化合物(PAINS:Pan Assay INterference compoundS)などの問題構造を検出するフィルターカタログが用意されています。
- PAINS_A / PAINS_B / PAINS_C:3段階のPAINSサブセット
- BRENK:望ましくない官能基
- ZINC:ZINCデータベースの除外パターン
- NIH:NIH推奨の不適格構造
from rdkit.Chem import FilterCatalog
params = FilterCatalog.FilterCatalogParams()
params.AddCatalog(FilterCatalog.FilterCatalogParams.FilterCatalogs.PAINS)
catalog = FilterCatalog.FilterCatalog(params)
entry = catalog.GetFirstMatch(mol)
if entry:
print(f"PAINS hit: {entry.GetDescription()}")7.実践的なAI創薬パイプラインへの組み込み
これらの指標は、生成AIの報酬関数や、化合物ライブラリの多段階フィルタリングで組み合わせて使われます。
def drug_discovery_pipeline(smiles_list):
results = []
for smiles in smiles_list:
mol = Chem.MolFromSmiles(smiles)
if mol is None:
continue
# ① PAINSフィルター
if catalog.GetFirstMatch(mol):
continue
# ② QEDによる薬物類似性
qed = QED.default(mol)
if qed < 0.3:
continue
# ③ SA Scoreによる合成性
sa = sascorer.calculateScore(mol)
if sa > 6:
continue
results.append({'smiles': smiles, 'qed': qed, 'sa': sa})
return results強化学習で分子生成を行う場合は、QED・SA・NPを重み付けして報酬として与える設計が一般的です。たとえば「QED 0.4・(10−SA)/9 で正規化したSAスコア 0.4・正規化NP 0.2」のような線形結合で評価できます。
8.まとめと推奨閾値
主要指標の用途と推奨閾値を以下にまとめます。
- SA Score:合成容易性評価/推奨閾値 ≤ 4(合成可能)/≤ 6(要検討)
- QED:総合的薬物類似性/推奨閾値 ≥ 0.5(良好)/≥ 0.3(最低限)
- NP Score:天然物類似性/天然物指向設計では > 0 を目安
- SPS / nSPS:空間的複雑性/低いほど合成しやすい傾向
- PAINS:アッセイ干渉排除/ヒットなしを必須条件に
RDKit Contribの補助指標を活用することで、AI創薬における「生成と合成のギャップ」を埋め、現実的な創薬候補へと絞り込むパイプラインを構築できます。これらは単独で使うよりも、目的に応じて複数を組み合わせ、生成AIの報酬設計やライブラリスクリーニングの多段階フィルターとして活用するのが実践的です。
参考文献・関連リンク
- Ertl P, Schuffenhauer A. Estimation of synthetic accessibility score of drug-like molecules based on molecular complexity and fragment contributions. J Cheminform. 2009;1:8. DOI: 10.1186/1758-2946-1-8
- Bickerton GR, Paolini GV, Besnard J, Muresan S, Hopkins AL. Quantifying the chemical beauty of drugs. Nat Chem. 2012;4(2):90-98. DOI: 10.1038/nchem.1243
- RDKit公式ドキュメント:
https://www.rdkit.org/docs/ - RDKit GitHub Contribディレクトリ:
https://github.com/rdkit/rdkit/tree/master/Contrib - Greg Landrum’s RDKit Blog(SA/NP Score使用法):
https://greglandrum.github.io/rdkit-blog/posts/2023-12-01-using_sascore_and_npscore.html - RDKit Spacial Scoreドキュメント:
https://rdkit.org/docs/source/rdkit.Chem.SpacialScore.html
免責事項
本記事は、RDKit Contribおよび関連する化学情報処理指標に関する情報提供を目的として作成されたものです。記事の内容は、公開時点で入手可能な文献・公式ドキュメントに基づいていますが、ライブラリの仕様やAPI、推奨閾値は今後変更される可能性があります。記事に記載されたコード例の使用結果や、それに基づく研究成果について、筆者および本ブログは一切の責任を負わないものとします。実際の創薬研究や論文発表にあたっては、必ず最新の公式ドキュメント・原論文を確認してください。
本記事は生成AIを活用して作成しています。内容については十分に精査しておりますが、誤りが含まれる可能性があります。お気づきの点がございましたら、コメントにてご指摘いただけますと幸いです。
本記事に関連するおすすめ書籍をご紹介します。
Amazonでこの関連書籍「化学のためのPythonによるデータ解析・機械学習入門(改訂2版)」を見る