
1.はじめに
機械学習モデルが「90%の確率で活性あり」と予測した化合物が、実際に活性を示す割合は本当に90%なのでしょうか。AI創薬では予測値そのものだけでなく、その予測がどれほど信頼できるか(不確実性)を正しく評価することが、研究開発の意思決定を左右します。
本記事では、機械学習モデルの予測確率を「実際の確率」に近づけるためのPythonライブラリ「NetCal(net:cal calibration framework)」について、AI創薬における意義・主要手法・活用事例を、医療関係者向けにわかりやすく解説します。
2.確率のキャリブレーションとは?AI創薬で重要視される理由
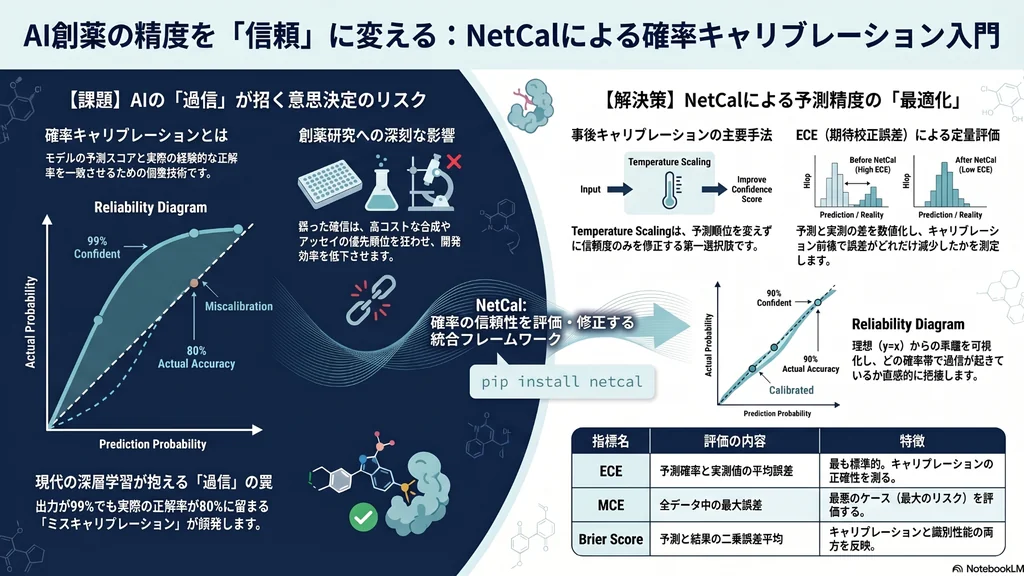
確率のキャリブレーション(Probability Calibration)とは、機械学習モデルが出力する予測スコアと、実際の経験的な正解率を一致させるための調整技術です。分類タスクでは「同じ予測確率を持つサンプル群における経験的な正解率と、その予測確率が一致している状態」が理想とされます。たとえば「70%の確率で結合する」と予測された化合物群があれば、その中で実際に結合する割合も70%に近いことが望まれます。
しかし、現代の深層学習モデルは「過信(overconfidence)」しやすい性質を持ちます。ソフトマックス出力の最大値が0.99でも、実際の正解率は80%程度にとどまる場合があり、これをミスキャリブレーションと呼びます。創薬では誤った確信が高コストな実験の優先順位を狂わせるため、看過できない問題です。
特に薬剤-ターゲット相互作用(DTI:Drug-Target Interaction)予測や分子特性予測(毒性・溶解度など)では、予測の信頼性が次のステップである合成・アッセイの可否判断に直結します。キャリブレーションが不適切だと、不確実性に基づく意思決定そのものが揺らいでしまうのです。
3.NetCalとは?Python製のキャリブレーション統合ライブラリ
NetCal(net:cal calibration framework)は、ニューラルネットワークなどの機械学習モデルが出力する信頼度や不確実性推定のミスキャリブレーションを測定し、軽減するためのPythonライブラリです。ドイツのRuhr West応用科学大学とe:fs TechHub GmbHが共同で公開している、オープンソースの統合フレームワークです。創薬専用ツールではなく、汎用のキャリブレーションライブラリという位置づけになります。
分類タスク・回帰タスク・物体検出など複数のドメインを単一のAPIで扱えるのが特徴で、ECE(Expected Calibration Error:期待校正誤差)やNLL(Negative Log-Likelihood:負の対数尤度)などの評価指標、信頼度図(Reliability Diagram)の可視化機能までを一通り備えています。
創薬関連の分子機械学習研究でも、NetCalなどのキャリブレーションライブラリを用いた事後キャリブレーションの利用例が報告されています。たとえば分子機械学習における不確実性キャリブレーションの比較研究では、netcalライブラリを用いたパラメトリック手法による校正が実装されています。既存モデルの出力に対する事後処理として組み込みやすい点が魅力です。
4.NetCalが提供する主要なキャリブレーション手法
NetCalは多数の校正手法を実装しており、本記事では理解のためにビニング系・スケーリング系・正則化系の観点で整理します(公式APIの分類とは必ずしも一致しません)。それぞれの代表的な手法は以下の通りです。
4.1. ビニング手法(Binning Methods)
- Histogram Binning:予測値を一定数のビンに分け、各ビン内の実際の正解率を割り当てる単純で頑健な手法
- Isotonic Regression:モデルスコアに対して単調増加関数で回帰し、ノンパラメトリックに校正する手法
- BBQ(Bayesian Binning into Quantiles):分位数に基づくベイズ的なビニング
- ENIR:近似的アイソトニック回帰のアンサンブル
4.2. スケーリング手法(Scaling Methods)
- Logistic Calibration / Platt Scaling:シグモイド関数を用いて出力スコアを確率に変換する古典的手法
- Temperature Scaling:単一の温度パラメータTでソフトマックス出力を平滑化または尖鋭化する手法
- Beta Calibration:Beta分布を用いた柔軟なスケーリング
- Dependent Logistic / Beta Calibration:物体検出における依存関係を考慮したスケーリング
4.3. 回帰用の不確実性キャリブレーションと学習時正則化
回帰タスクには、Variance Scaling(分散スケーリング)、GP-Normal・GP-Cauchy・GP-Beta(ガウス過程ベース)が用意されています。また学習時に組み込む正則化として、Confidence Penalty、MMCE(Maximum Mean Calibration Error)、DCA(Decorrelated Confidence Aggregation)などが提供されています。
5.代表手法の詳細:Temperature ScalingとPlatt Scaling
5.1. Temperature Scaling:シンプルで強力な過信の抑制
Temperature Scalingは、ソフトマックス関数に単一の温度パラメータTを導入し、ロジット(最終層の生スコア)をTで割ってから確率化する手法です。T > 1 で確率分布を平滑化(過信を抑制)し、T < 1 で尖鋭化します。たった1つのパラメータを検証データで最適化するだけで、ECEを大幅に改善できることが知られています。
実装が極めて簡単で、通常は分類ラベルの予測自体(argmaxの結果)を変えずに信頼度だけを校正できる点が大きな利点です。学習済みの深層学習モデルに後付けで適用できるため、事後キャリブレーションの第一選択肢として広く使われています(クラス別スケーリングなどでは順位保存が成り立たない場合もあります)。
5.2. Platt Scaling:シグモイド関数で確率に変換
Platt Scaling(Logistic Calibration)は、もともとSVM(サポートベクターマシン)の出力スコアを確率に変換するために開発された手法です。シグモイド関数 P(y=1|x) = 1 / (1 + exp(A·f(x) + B)) によりスコアをマッピングし、AとBの2パラメータを学習します。二値分類で広く利用されています。
6.AI創薬でのNetCal活用事例:DTI予測と分子特性予測
6.1. 薬剤-ターゲット相互作用(DTI)予測での包括的研究
2025年にPMCで公開された研究「Achieving well-informed decision-making in drug discovery」では、ニューラルネットワークに基づく構造活性モデルのキャリブレーションが包括的に検証されました。注目すべき発見は、ハイパーパラメータの選択基準がキャリブレーション性能を大きく左右するという点です。
精度やAUCを最大化するチューニングよりも、BCE損失やACE(Adaptive Calibration Error)を最適化するチューニングの方が、良好なキャリブレーションを達成することが示されました。さらに同論文は、HMC Bayesian Last Layer(HBLL)という計算効率の良いベイズ的不確実性推定法を提案し、同研究の評価設定ではMC DropoutやDeep Ensemblesなどの既存手法と同等以上の性能を示したと報告しています(性能の優劣はデータセット・指標・設定に依存するため、個別検証が必要です)。
6.2. 分子特性予測:分布外(OOD)への過信を点検する補助手段
分子特性予測においても、キャリブレーションは「学習データの分布から外れた分子(OOD:Out-of-Distribution)」に対するモデルの過信を点検する補助的な観点として有用です。ただし、キャリブレーション単独でOOD分子を確実に検出できるわけではなく、スキャフォールド分割、適用範囲(applicability domain)の評価、外部検証データでの検証と組み合わせて運用する必要があります。
分類タスクでは予測確率と経験的正解率の一致が主な評価対象となるのに対し、回帰タスクでは予測区間・分散・分位点の妥当性が評価の中心になります。AUCが高くても校正が悪い場合があり、逆に校正が改善してもランキング性能(識別性能)が改善するとは限らないため、両者は分けて検討することが大切です。
7.NetCalの使い方:インストールと基本コード
NetCalはpipで簡単にインストールできます。2026年時点の公式リポジトリでは、最新版(1.4.0、2026年4月リリース)はPython 3.10以上が要求されています。利用時は公式GitHubやPyPIで対応Pythonバージョンと依存ライブラリを必ず確認してください。
pip install netcalTemperature Scalingを用いた基本的な使用例は以下の通りです。検証データでフィットさせ、テストデータの確率を校正し、ECEで前後を比較する流れです。
from netcal.scaling import TemperatureScaling
from netcal.metrics import ECE
temperature = TemperatureScaling()
temperature.fit(confidences, ground_truth)
calibrated = temperature.transform(test_confidences)
ece = ECE(bins=10)
uncalibrated_error = ece.measure(test_confidences, test_ground_truth)
calibrated_error = ece.measure(calibrated, test_ground_truth)
print(f"ECE before: {uncalibrated_error:.4f}")
print(f"ECE after: {calibrated_error:.4f}")
リポジトリURL:https://github.com/EFS-OpenSource/calibration-framework
8.キャリブレーション評価指標と信頼度図の活用
NetCalは以下の主要な評価指標を提供しています。いずれも一般に値が小さいほど望ましいですが、評価対象は指標ごとに異なります(ECE系は校正誤差、Brier ScoreやNLLは校正に加えて識別性能や鋭さも反映します)。
- ECE(Expected Calibration Error):予測確率と実際の正解率の差をビンごとに加重平均した最も標準的な指標
- MCE(Maximum Calibration Error):すべてのビン中で最大の誤差。最悪ケースを評価
- ACE(Adaptive Calibration Error):サンプル数が均等になるよう適応的にビニング
- Brier Score:予測確率と実際の結果の二乗誤差平均
- NLL(Negative Log-Likelihood):負の対数尤度
定量指標と併せて、信頼度図(Reliability Diagram)による可視化も欠かせません。横軸に予測確率、縦軸に実際の正解率をとり、理想的な対角線(y=x)からの乖離を確認することで、どの確率帯で過信または過小評価が起きているかを直感的に把握できます。
9.まとめ:NetCalで「予測の確からしさ」を点検する
NetCalは、AI創薬を含む機械学習タスクにおいて、予測確率や不確実性推定の信頼性を評価・改善するための汎用Pythonライブラリです。Temperature ScalingやPlatt Scaling、ECE、信頼度図などを使うことで、モデルがどの程度過信または過小評価しているかを定量的に検討できます。
「予測値」だけでなく「予測の確からしさ」までを点検できることは、候補化合物の優先順位付けを支援する有用な情報になります。ただし、校正された予測確率は実験的有効性や安全性を保証するものではなく、本記事の内容も研究段階の意思決定支援を想定したものであり、臨床応用の安全性確認とは区別して扱う必要があります。DTI予測や分子特性予測に取り組まれている方は、まずTemperature Scalingから試し、検証データでの信頼度図の改善を確認してみてください。
参考文献・リンク
- net:cal calibration framework – GitHub
- net:cal 公式ドキュメント
- netcal – PyPI
- Achieving well-informed decision-making in drug discovery (2025) – PMC
- Uncertainty Calibration in Molecular Machine Learning – Wiley
Amazonでこの関連書籍「ベイズ深層学習(機械学習プロフェッショナルシリーズ)」を見る
免責事項
本記事は、AI創薬における確率のキャリブレーション(NetCalフレームワーク)に関する情報提供を目的として作成されたものです。記事の内容は、公開時点で入手可能な文献・情報に基づいていますが、技術の進歩や新たな知見により、情報が変更される場合があります。記事に記載されたソフトウェアの使用結果や、それに基づく研究成果について、筆者および本ブログは一切の責任を負わないものとします。実際の創薬研究や臨床応用にあたっては、必ず最新の文献・公式ドキュメントを確認し、専門家の助言を得てください。
本記事は生成AIを活用して作成しています。内容については十分に精査しておりますが、誤りが含まれる可能性があります。お気づきの点がございましたら、コメントにてご指摘いただけますと幸いです。
Amazonでこの関連書籍「ベイズ深層学習(機械学習プロフェッショナルシリーズ)」を見る