
1. はじめに:なぜ今、医療現場や研究で「タンパク質データ」が重要なのか
現代の医療において、私たちが目にする薬の多くは、体内の特定の「タンパク質」に働きかけることで効果を発揮します。がん細胞の増殖を抑える分子標的薬も、ウイルスの複製を防ぐ抗ウイルス薬も、その設計図の源流をたどれば、タンパク質の精密な構造と機能の情報に行き着きます。
近年、AI(人工知能)を用いた創薬、いわゆる「AI創薬」が急速に普及していますが、そのAIに「学習」させるための最も信頼できる教科書として君臨しているのが、今回ご紹介するUniProt(ユニプロット)です。世界中の研究者が参照するこの巨大な知識ベースが、どのように私たちの未来の医療を作っているのか、専門家の視点から詳しく紐解いていきましょう。
2. ステップ1:UniProt(ユニプロット)の正体を知る
2.1. 世界最大級のタンパク質カタログ
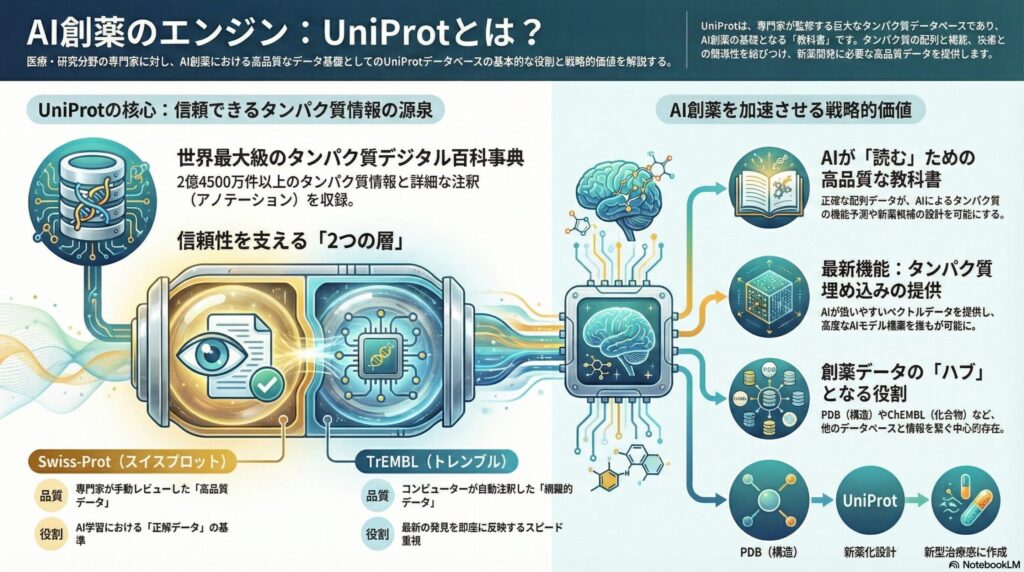
UniProt(Universal Protein Resource)は、一言で言えば「世界中のタンパク質情報を集約したデジタル百科事典」です。欧州とスイスの専門機関が共同運営しており、2024年時点で2億4500万件を超えるタンパク質の情報を保有しています。
このデータベースが特別なのは、単に「名前」や「並び順」を記録しているだけでなく、そのタンパク質が「体内のどこで働くのか」「どんな病気に関わっているのか」といった膨大な注釈(アノテーション)が付加されている点にあります。
2.2. 医療における信頼の基盤
医療関係者の皆様にとって馴染み深い、疾患関連遺伝子から作られるタンパク質の性質も、UniProtを基盤として解析されています。いわば、創薬という長い航海における「最も正確な地図」と言えるでしょう。
3. ステップ2:UniProtKBを構成する「2つの層」の違いを理解する
UniProtの核となる「UniProtKB」は、データの信頼性と網羅性のバランスを取るために、大きく2つのカテゴリーに分かれています。この違いを理解することが、データを正しく扱う第一歩です。
3.1. Swiss-Prot(スイスプロット):プロが磨き上げた「至高のデータ」
Swiss-Protは、バイオキュレーターと呼ばれる専門家が、世界中の論文を読み込み、実験結果を確認した上で手動で情報を整理したセクションです。
- 特徴: 非常に高品質で、誤りが極めて少ない。
- 内容: 機能、疾患との関連、翻訳後修飾(タンパク質が作られた後の変化)などが詳細に記されています。
- 価値: AIの学習において「正解ラベル」として使われる、いわばゴールドスタンダードです。
3.2. TrEMBL(トレンブル):最新情報をカバーする「スピードのデータ」
一方で、ゲノム解析技術の向上により、毎日膨大な数の新しい配列が見つかっています。これらすべてを人間が確認するのは不可能です。そこで、コンピューターが自動的に注釈を付けたのがTrEMBLです。
- 特徴: 圧倒的なデータ量を誇り、最新の発見を即座に反映します。
- 注意点: 自動解析のため、Swiss-Protに比べると情報の精度にばらつきがある場合があります。
4. ステップ3:AI創薬を加速させる「UniProt」の戦略的価値
AIは魔法ではありません。良質な「データ」を食べて成長します。UniProtがAI創薬においてどのように貢献しているのか、具体的な3つの側面を見てみましょう。
4.1. アミノ酸配列から「機能」を読み解く
タンパク質は20種類のアミノ酸が鎖状につながったものです。AIはこの配列を「文章」のように読み取ります。UniProtの正確な配列データを使うことで、AIは「この並び順なら、このタンパク質はがんの増殖に関わっているはずだ」といった予測を高精度に行えるようになります。
4.2. 特徴量エンジニアリングと学習
タンパク質の性質を数値化することを特徴量エンジニアリングと呼びます。UniProtのデータは、タンパク質の重さや水への溶けやすさなど、機械学習モデルが理解しやすい形に変換され、新薬の候補化合物がそのタンパク質に「くっつくかどうか」を判定する材料になります。
4.3. 生成AIとの融合
最近では「ChatGPT」のような大規模言語モデル(LLM)の技術をタンパク質に応用する研究が進んでいます。UniProtの膨大な配列を学習した生成AIは、自然界には存在しないが特定の病気に効く「新しいタンパク質」をゼロから設計(de novo設計)することすら可能にしています。
5. ステップ4:2025年〜2026年の最新イノベーション
UniProtは常に進化しています。特に直近で実装された機能は、創薬の効率を劇的に変える可能性を秘めています。
5.1. タンパク質埋め込み(Protein Embeddings)の提供
これが最も革新的な変化の一つです。「埋め込み」とは、タンパク質の複雑な性質をAIが扱いやすい「多次元のベクトル(座標)」に変換したものです。 これまでは研究者が個別に計算していましたが、UniProtが公式にこのデータを提供し始めたことで、誰もが即座に高度なAIモデルを構築できるようになりました。
5.2. ゲノミクスタブの実装
医療現場のニーズに応える機能として、タンパク質データとゲノム(遺伝子)の座標を直結させる「ゲノミクスタブ」が登場しました。これにより、「患者さんのこの遺伝子変異が、タンパク質のどの部分に影響を与え、病気を引き起こしているのか」をシームレスに確認できるようになりました。
5.3. 抗菌薬抵抗性(AMR)への集中対策
世界的な脅威となっている薬剤耐性菌。UniProtは、耐性菌が持つ特定のタンパク質(ベータラクタマーゼなど)を集中的に調査・整理しています。これにより、既存の薬が効かない菌に対抗する「次世代の抗菌薬」の開発が加速しています。
6. ステップ5:実践!創薬ワークフローでの活用イメージ
では、実際に製薬企業や研究機関ではUniProtをどう使っているのでしょうか。標準的な流れ(ワークフロー)を例に挙げてみます。
- ターゲットの選定: 研究者が興味のある病気に関連するタンパク質(ターゲット)のリスト(例:500個)を準備します。
- UniProtでの品質チェック: 「実験的に存在が証明されているか(Protein level)」という基準でフィルタリングを行い、信頼性の高いターゲットだけに絞り込みます。
- 他のデータベースとの連携: UniProtのIDを鍵にして、PDB(構造データベース)から3D構造を取得し、ChEMBL(化合物データベース)から過去に試された薬の情報を統合します。
このように、UniProtはバラバラに存在する情報を一つに繋ぎ合わせる「ハブ」の役割を果たしているのです。
7. おわりに:UniProtが切り拓く個別化医療の未来
UniProtの進化は、単なるデータの蓄積に留まりません。将来的には、一人ひとりの患者さんが持つ微細なタンパク質の個性を反映した「デジタルツイン(仮想的な生体モデル)」をAI上に構築し、どの薬が最も効果的で副作用が少ないかを事前にシミュレーションできるようになるでしょう。
医療関係者の皆様にとって、UniProtは遠い世界のデータベースではなく、日々の診療や研究の背景を支える「インテリジェンス・プラットフォーム」へと変貌を遂げています。この「タンパク質地図」を味方につけることが、AI時代の医療をリードする鍵となるはずです。
免責事項
本記事は、公開時点(2026年1月)の信頼できる情報に基づいて作成されていますが、UniProt等のデータベースの仕様変更や学術的な新発見により、内容が更新される可能性があります。情報の正確性については細心の注意を払っておりますが、実際の研究や臨床、投資判断等に際しては、必ず公式の一次ソースをご確認ください。なお、本記事の利用によって生じたいかなる損害についても、当ラボおよび筆者は一切の責任を負わないものとします。
本記事は生成AI (Gemini) を活用して作成しています。内容については十分に精査しておりますが、誤りが含まれる可能性があります。お気づきの点がございましたら、コメントにてご指摘いただけますと幸いです。
Amazonでこの関連書籍「Searching in Protein Databases. 2nd Edition: Algorithms for secure protein submission and faster searching」を見る