
1. はじめに:デジタル時代の創薬に不可欠な「知の宝庫」
現代の創薬シーンは、従来の「偶然の発見」から「データ駆動型の設計」へと劇的な変貌を遂げています。その中心にあるのが、膨大な実験データを集約したデータベースの存在です。
今回ご紹介する「BindingDB」は、タンパク質と小分子(薬の候補となる物質)の間に働く「結びつきの強さ」を記録した、世界初の公開データベースです。医療現場で使われる薬が、どのようにして標的に作用するかを理解するための、いわば「設計図の集積所」と言えるでしょう。
2. BindingDBの基礎知識:なぜこのデータベースが重要なのか
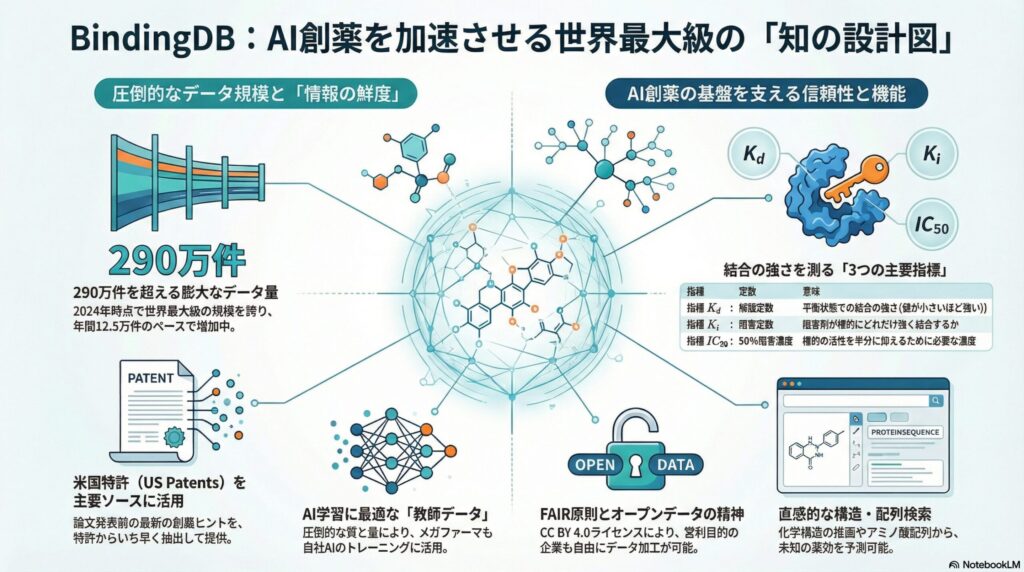
BindingDBは、タンパク質とリガンド(結合する分子)の結合親和性を中心に扱う、世界最大規模の公共リソースです。2024年時点で、そのデータ量は290万件を超え、日々増殖を続けています。
ここで重要となる「結合親和性」とは、鍵(薬)が鍵穴(タンパク質)にどれだけぴったりとはまり、外れにくいかを示す指標です。この数値が正確であればあるほど、副作用が少なく、効果の高い薬をコンピュータ上で予測することが可能になります。
BindingDBが画期的なのは、これほど質の高い膨大なデータを、世界中の研究者が「無料」で利用できる点にあります。これにより、製薬企業だけでなくアカデミアの創薬研究も飛躍的にスピードアップしました。
3. 特許データが支える圧倒的な情報量と「鮮度」
BindingDBの最大の強みは、情報源の選び方にあります。一般的なデータベースが学術論文を主なソースとするのに対し、BindingDBは**米国特許(US Patents)**からのデータ抽出に心血を注いでいます。
製薬企業が新しい化合物を開発した際、論文として発表されるよりも先に特許として出願されることが多々あります。つまり、特許を網羅することは「世界で最も新しい創薬のヒント」をいち早くキャッチすることを意味します。
年間約12万5,000件ものペースで追加されるデータは、AI(人工知能)が学習するための良質な教師データとなります。この圧倒的な「情報の鮮度」こそが、BindingDBを創薬研究のスタンダードたらしめている理由です。
4. 数値で見る信頼性:Kd、Ki、IC50の重要性
BindingDBには、結合の強さを表す3つの主要な指標が格納されています。これらは医療統計や薬理学でも頻出する重要な数値です。
- Kd(解離定数): 平衡状態での結合の強さ。値が小さいほど結合が強い。
- Ki(阻害定数): 阻害剤が酵素などにどれだけ強く結合するかを示す。
- IC50(50%阻害濃度): 標的の活性を半分に抑えるために必要な濃度。
これらの数値は、実験条件(温度、pH、使用されたバッファーなど)と共に詳細に記録されています。単なる数字の羅列ではなく、その数値が「どのような環境で導き出されたか」という文脈まで保存されている点が、プロの研究者に支持される理由です。
5. 検索機能の進化:必要な情報を瞬時に引き出す
BindingDBは、ITに詳しくない研究者でも直感的に操作できるよう設計されています。代表的な検索方法は、化学構造、配列、キーワードの3つです。
化学構造検索では、手元にある化合物のイラストを描くことで、それに似た構造を持つ物質が過去にどのようなタンパク質と結合したかを調べられます。これは、既存薬の「新しい効能」を見つける(ドラッグ・リポジショニング)際にも極めて有効です。
また、タンパク質の配列(アミノ酸の並び)を用いたBLAST検索も可能です。これにより、未知のタンパク質に対して、既知の薬が作用する可能性があるかどうかを、相同性(似ている度合い)に基づいて予測することができます。
6. FAIR原則とオープンデータの精神
BindingDBは「FAIR原則」という、データの利活用における国際的な指針を厳守しています。これは、データを「見つけやすく、アクセスでき、相互運用が可能で、再利用できる」ようにするためのルールです。
この原則に基づき、BindingDBのデータは「CC BY 4.0」というライセンスで公開されています。これは、出典さえ明記すれば、営利目的の企業であっても自由にデータを加工し、自社のAIモデル構築に利用できることを意味します。
データの信頼性を担保するため、カリフォルニア大学サンディエゴ校(UCSD)の図書館が長期保存をサポートするなど、インフラ面でのバックアップも万全です。一度登録されたデータが消えてしまうリスクが低く、安心して研究の基盤に据えることができます。
7. AI・機械学習との融合:次世代創薬のプラットフォーム
現在、BindingDBの最もホットな活用先は「AI創薬」です。ディープラーニングなどの技術を用いて、未知の化合物が病気の原因タンパク質に結合するかどうかを、一瞬で予測するモデルの開発が進んでいます。
AIに学習させるためには、数百万件規模の「正解データ」が必要です。BindingDBは、その規模と精度の両方を満たす稀有なリソースです。実際に、世界中のAIベンチャーやメガファーマが、このデータベースを自社AIのトレーニングに活用しています。
さらに、PDB(Protein Data Bank)との連携により、3次元的な構造情報も付与されています。これにより「なぜこの薬はこの位置に結合するのか?」という空間的な解析も可能になり、より精密な分子設計が可能になっています。
8. 今後の展望:進化し続けるBindingDB
2024年以降、BindingDBはさらにユーザーフレンドリーな進化を遂げようとしています。スマートデバイスからのアクセスを最適化するレスポンシブデザインの導入により、研究室のベンチや移動中でもデータを手軽にチェックできるようになりました。
また、今後は「CoreTrustSeal」という、データの信頼性に関する国際認証の取得も目指しています。これにより、BindingDBに掲載されているデータが、これまで以上に高い学術的価値を持つことが公的に証明されることになります。
創薬研究は、今や一国や一企業の努力だけで完結するものではありません。BindingDBのような公共データベースがハブとなり、世界中の知見が共有されることで、これまで治療法がなかった難病に対する新薬が一日も早く誕生することが期待されています。
9. おわりに:専門家としての視点
トップクラスの創薬・AI専門家として断言できるのは、BindingDBを知らずして現代のデジタル創薬は語れないということです。その網羅性と透明性は、学術界と産業界の架け橋となっており、今後その重要性はさらに高まるでしょう。
この記事を通じて、BindingDBが単なるデータの数字の集まりではなく、人類が病に立ち向かうための「知恵の結晶」であることを感じていただければ幸いです。
免責事項
本記事に掲載されている情報は、執筆時点での公開データに基づき細心の注意を払って作成されていますが、その正確性や完全性を永久に保証するものではありません。本情報の利用によって生じたいかなる損害についても、当方では一切の責任を負わないものとします。最新の仕様については、必ずBindingDB公式サイト(bindingdb.org)をご確認ください。
本記事は生成AI (Gemini) を活用して作成しています。内容については十分に精査しておりますが、誤りが含まれる可能性があります。お気づきの点がございましたら、コメントにてご指摘いただけますと幸いです。
Amazonでこの関連書籍「インシリコ創薬: 計算創薬の基礎から実例まで」を見る