
1.はじめに:なぜ今、分子の「数値化」が必要なのか
現代の創薬シーンにおいて、AI(人工知能)や機械学習の活用はもはや無視できない潮流となっています。新薬の候補となる化合物を見つけ出し、その有効性や安全性を予測するためには、コンピューターが理解できる形で「分子の特徴」を伝える必要があります。
私たちは、医師や薬剤師が処方箋を読み解くように、コンピューターに化合物の構造を理解させなければなりません。そのための「翻訳機」の役割を果たすのが、今回ご紹介する「Mordred(モルドレッド)」というツールです。本記事では、Mordredの基礎から実践的な活用法までを、医療関係者の皆様に向けて分かりやすく解説します。
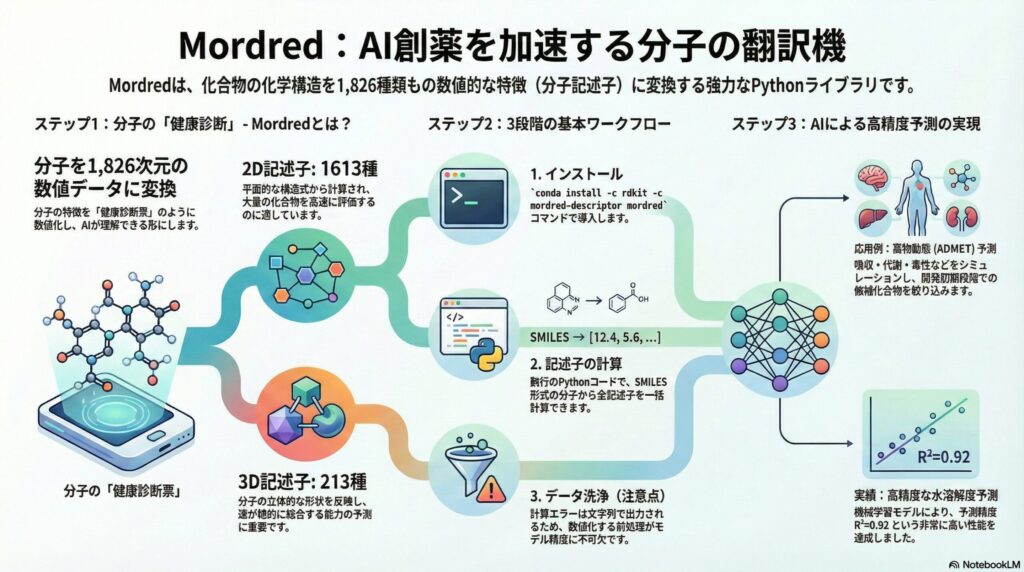
2.ステップ1:分子記述子の正体を知る ― 分子の「健康診断票」
まず「分子記述子(ぶんしきじゅつし)」という言葉に馴染みのない方も多いかもしれません。これは、一言で言えば「分子の特徴を数値で表したもの」です。人間で例えるなら、身長、体重、血圧、血糖値といった「健康診断の結果」のようなものだと考えてください。
例えば、ある薬の「水への溶けやすさ(脂溶性)」や「分子の重さ(分子量)」、さらには「水素結合に関わる部位がいくつあるか」といった情報を、一つひとつ数字として書き出したものが分子記述子です。Mordredは、この数値をなんと1,826種類も、一瞬で計算してくれる非常に優れたツールなのです。
これほど多くのデータを集める理由は、薬の候補が体にどう吸収され、どう代謝されるか(ADME)を精密に予測するためです。わずかな構造の違いが、臨床現場での薬効や副作用の差として現れるため、多角的なデータが必要になります。
3.ステップ2:Mordredが提供する1,826種類の情報の内訳
Mordredが計算する記述子は、大きく分けて「2D記述子」と「3D記述子」の2種類があります。2D記述子は、紙に書いた構造式から得られる情報です。原子の数や結合の種類、芳香族性(環状構造の安定性)などが含まれます。これらは計算が非常に速く、大量の化合物をスクリーニングするのに適しています。
一方、3D記述子は、分子が空間の中でどのような形をしているか(立体構造)に着目した情報です。薬が受容体(ターゲットタンパク質)に鍵と鍵穴のように結合するためには、この立体的な形状が極めて重要になります。Mordredは、これら両方の視点から分子を解剖します。
具体的には、リピンスキーの「Rule of Five(経口薬としての適性を測る指標)」のような有名な指標から、原子同士の電気的な引き合いを示す「電荷記述子」まで、創薬研究に必要なほぼすべてのパラメータを網羅しています。これにより、私たちは分子を多次元的な視点で評価できるようになるのです。
4.ステップ3:環境構築と導入 ― Pythonの力を借りる
Mordredを使用するためには、プログラミング言語の「Python(パイソン)」という環境が必要です。最近では、データサイエンスに携わる医師や薬剤師の間でも広く普及している言語です。導入は非常にシンプルで、専用のコマンドを入力するだけで完了します。
推奨されるインストール方法は「Conda(コンダ)」というパッケージ管理システムを使う方法です。以下のコマンドを実行することで、化学情報学の標準ライブラリである「RDKit」と共にMordredがインストールされます。
conda install -c rdkit -c mordred-descriptor mordred
プログラミングと聞くと難しく感じるかもしれませんが、Mordredの設計は非常にユーザーフレンドリーです。一度環境を整えてしまえば、あとは数行のコードを書くだけで、数千個の化合物のデータを一括で処理することが可能になります。この効率性は、手作業でデータを集めていた従来の研究スタイルを劇的に変える力を持っています。
5.ステップ4:実践!分子をデータに変換するプロセス
環境が整ったら、実際に化合物をMordredに読み込ませてみましょう。創薬の世界で一般的に使われる「SMILES(スマイルズ)」という形式の文字列を使って分子を指定します。例えば、ベンゼンであれば c1ccccc1 と記述します。
PythonのライブラリとしてMordredを呼び出し、計算機(Calculator)を起動させると、指定した分子の1,826種類の記述子がリストとして出力されます。これを「Pandas(パンダス)」というデータ解析ライブラリと組み合わせることで、Excelのような表形式で簡単に扱うことができます。
「この分子は、既存の薬と比べてどの程度形が似ているのか?」「副作用が懸念される構造が含まれていないか?」といった分析が、すべて数値ベースで行えるようになります。医療統計に慣れている方であれば、このデータの山がどれほど強力な武器になるか想像に難くないでしょう。
6.ステップ5:計算結果の「落とし穴」とデータ洗浄のコツ
Mordredを使用する上で、専門家として最も注意を促したいのが「欠損値(計算エラー)」の処理です。実は、すべての分子ですべての項目が計算できるわけではありません。例えば、特定の原子ペアが存在しない場合や、計算式が定義できない構造の場合、Mordredは「エラー(NaN:Not a Number)」を返します。
ここが重要なのですが、Mordredはエラーを単なる空白ではなく、「エラーメッセージという文字列」として返すことがあります。これを知らずに統計解析ソフトに読み込ませると、エラーが発生して計算が止まってしまいます。そのため、事前の「データクレンジング(洗浄)」が必須です。
具体的には、エラーが含まれる列を特定して除外したり、平均値で補完したりする作業を行います。医療データの解析において外れ値を処理するのと同様に、創薬データでもこの「丁寧な前処理」が予測モデルの精度を左右します。質の高いデータこそが、質の高いAIを生むのです。
7.ステップ6:医療・創薬現場での具体的な活用例
Mordredで得られた膨大なデータは、具体的にどのように役立つのでしょうか?最も代表的な例は「薬物動態の予測(ADMET予測)」です。例えば、新しい化合物が腸管からどれくらい吸収されるか、肝臓でどのように代謝されるか、あるいは心臓に毒性がないか、といったことを実験前にシミュレーションできます。
ある研究では、Mordredの記述子を用いた機械学習モデルによって、化合物の水溶解度をR²=0.92という極めて高い精度で予測することに成功しています。水に溶けにくい薬は体内に吸収されにくいため、この予測は製剤設計において非常に重要です。
また、既存の薬(既承認薬)の記述子を計算し、それと似たプロフィールを持つ未知の化合物を探す「ドラッグ・リポジショニング(既存薬の転用)」にも活用されています。臨床現場で使われている薬の知識と、Mordredによるデータ解析が組み合わさることで、新薬開発のスピードは飛躍的に向上します。
8.おわりに:AI創薬のパートナーとしてのMordred
Mordredは、単なる計算ツールではありません。それは、私たちが「化学構造」という複雑な対象を、論理的かつ客観的に理解するための「物差し」です。1,826種類もの記述子は、一見すると過剰に思えるかもしれませんが、その一つひとつが分子の個性を語る大切な言葉なのです。
医療関係者の皆様が、日々の臨床や研究の中で抱く「なぜこの薬は効くのか?」「もっと良い構造はないのか?」という問いに対し、Mordredはデータという明確な回答を提示する助けとなるでしょう。Pythonやデータサイエンスのスキルを少しずつ取り入れながら、ぜひこの強力なツールを自身の武器にしてみてください。創薬の未来は、データと臨床知見の融合の先にあります。
免責事項
本記事に掲載されている情報は、執筆時点での技術仕様および学術的知見に基づいています。Mordredのインストールや使用、および計算結果の解釈によって生じた不利益や損害について、当方は一切の責任を負わないものとします。プログラムの実行や研究への応用は、利用者の自己責任において行ってください。
本記事は生成AI (Gemini) を活用して作成しています。内容については十分に精査しておりますが、誤りが含まれる可能性があります。お気づきの点がございましたら、コメントにてご指摘いただけますと幸いです。
Amazonでこの関連書籍「マテリアルズインフォマティクス」を見る