
1. はじめに:なぜ今、天然物データベースが注目されるのか
現代医療において、新薬開発の難易度は年々高まっています。その中で、再び注目を集めているのが「天然物」です。私たちが日常的に処方する医薬品の多くは、植物や微生物が作り出す二次代謝物(にじたいしゃぶつ:生存に必須ではないが、特定の機能を持つ化合物)をヒントに開発されてきました。
しかし、自然界に存在する膨大な化合物と、それを含む生物種の情報を結びつける作業は困難を極めます。そこで登場したのが、日本が世界に誇るデータベース「KNApSAcK(ナップサック)」です。本記事では、医療関係者の皆様に向けて、この強力なツールの実体とその活用可能性を詳しく解説していきます。
2. KNApSAcKの正体―生物種と代謝物の架け橋
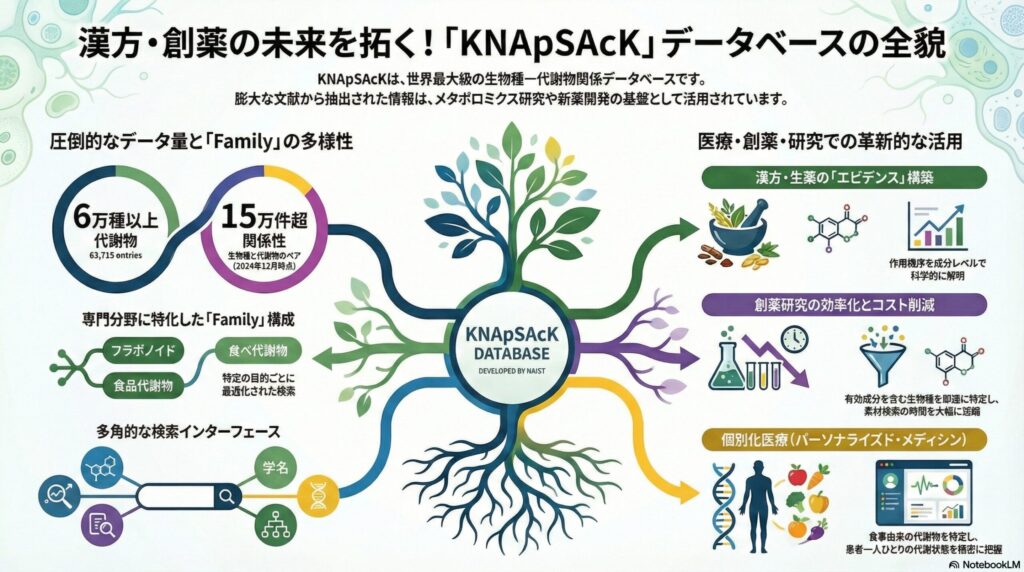
KNApSAcK(Knowledge Network for Applied Systems Biology and Knowledge)は、奈良先端科学技術大学院大学(NAIST)の金谷周彦教授らによって開発された、世界最大級の「生物種-代謝物関係データベース」です。その名の通り、必要な情報を「ナップサック」に詰め込んで持ち運ぶような利便性を目指しています。
このデータベースの最大の特徴は、単に化合物の構造を示しているだけではなく、「どの植物(あるいは微生物・動物)に、どの成分が含まれているか」という関係性を、膨大な科学文献から抽出して整理している点にあります。現在、11万種類以上の化合物と、それらを含む数万の生物種の情報が網羅されており、日々更新され続けています。
メタボロミクス(生体内の代謝物を網羅的に解析する手法)が臨床研究でも一般的になる中、未知のピーク(分析データ上の反応)が何の化合物であるかを特定するための「辞書」として、世界中の研究者に愛用されています。
3. 専門家も驚く「ファミリーデータベース」の多様性
KNApSAcKは、単一のデータベースではなく、特定の目的や化合物群に特化した「ファミリーデータベース」として構成されています。これにより、医療従事者が興味を持つ特定の分野に対して、より深く、精度の高い検索が可能となっています。
例えば「KNApSAcK Flavonoid」は、抗酸化作用や血管保護作用で知られるフラボノイド類に特化しています。また「KNApSAcK Phenylpropanoid」は、多くの生薬に含まれるフェニルプロパノイド系化合物を集中的に管理しています。これらのサブデータベースを活用することで、特定の薬理活性を持つ成分の分布を効率よく調査できます。
さらに、近年では「FoodMetablome」のように、食生活と健康を結びつけるデータも統合されつつあります。これにより、患者さんに提供する食事指導や、機能性食品のアドバイスにおいて、成分レベルでの裏付けを得ることが容易になっています。専門家にとって、この情報の層の厚さは非常に魅力的なポイントです。
4. 医療現場・創薬研究での具体的な活用シーン
では、具体的に医療関係者はどのようにKNApSAcKを活用できるのでしょうか。最も身近な例は、漢方薬(生薬)の作用機序の解明です。漢方薬は多成分系の薬剤であり、その全容を把握するのは困難ですが、KNApSAcKを用いれば、構成生薬に含まれる特徴的な代謝物を一挙にリストアップできます。
また、創薬研究においては「バイオアクティブ化合物(生物学的活性を持つ物質)」の探索に威力を発揮します。特定の受容体に作用しそうな化合物をデータベースで見つけた際、それをどの生物種から抽出すれば効率が良いかを即座に判断できるのです。これは、研究の初期段階における時間とコストの大幅な削減に直結します。
さらに、副作用の予測や相互作用の解析にも応用可能です。特定の代謝物が持つ構造的な特徴から、既存の医薬品との類似性を検索することで、予期せぬ薬物相互作用のヒントを得ることもあります。臨床現場での「なぜこの組み合わせが効くのか(あるいは悪影響なのか)」という疑問に対する、科学的な糸口を提供してくれるのです。
5. 高度な検索機能が導く「情報の可視化」
KNApSAcKが使いやすいと言われる理由の一つに、多角的な検索インターフェースがあります。一般的な名称検索(英名や学名)はもちろんのこと、化学構造式の一部を使った「構造類似性検索」や、質量分析(MS)で得られた分子量から成分を特定する「質量検索」も可能です。
医療現場の医師や薬剤師の方々が論文を執筆する際、臨床検体から検出された未知の物質について調査することがあるでしょう。その際、得られた分子量をKNApSAcKに入力するだけで、候補となる天然物成分とその由来生物がリストアップされます。これは、臨床データと生物学的背景を統合する上で非常に強力な武器となります。
また、生物の系統樹(系統的な親戚関係)と代謝物の分布を照らし合わせる機能もあります。これにより、「ある植物に有効成分が含まれているなら、その近縁種にも同様の、あるいはより強力な成分が含まれているのではないか」という仮説を立てることが可能になります。こうした予測機能は、AI時代の創薬において不可欠な要素となっています。
6. メタボロミクスと個別化医療への展望
今後の医療において、患者一人ひとりの代謝状態を把握する「個別化医療(パーソナライズド・メディシン)」の重要性は増すばかりです。KNApSAcKはこの分野においても、基盤となるデータプラットフォームとしての役割を期待されています。
血中や尿中の代謝物プロファイルを解析する際、それらが外因性(食事や薬物由来)なのか、内因性(ヒトの代謝由来)なのかを区別する必要があります。KNApSAcKの膨大な天然物・食品成分データは、こうした外因性因子の特定に大いに役立ちます。患者さんの生活習慣を、分子レベルで精密に把握することが可能になるのです。
また、AIや機械学習との統合も進んでいます。データベースに蓄積された膨大な「種-化合物」の関係性を学習させることで、まだ発見されていない新しい有効成分の存在や、その合成経路を予測する研究も進行中です。KNApSAcKは単なる過去の記録集ではなく、未来の治療法を生み出すための「知能」へと進化を遂げようとしています。
7. 利用方法と注意点―オープンサイエンスの活用
KNApSAcKは、学術利用であれば基本的に無料で公開されており、Webブラウザから誰でもアクセスすることが可能です。公式ウェブサイト(KNApSAcK Family)にアクセスし、メニューから目的の検索モードを選択するだけで、世界最先端の研究成果に触れることができます。
ただし、利用にあたってはいくつか注意点もあります。まず、データベースの情報は常に最新の論文に基づいたものですが、自然界の生物は個体差や生育環境によって含有成分が変動します。データベース上の数値はあくまで「その論文で報告された指標」であることを念頭に置く必要があります。
また、商用利用に関しては別途条件が設定されている場合がありますので、企業の製品開発などに利用する際は、公式サイトの利用規約を必ず確認してください。論文や学会発表で使用する際には、適切な引用を行うことが、この貴重な公共資産を維持・発展させていくための研究コミュニティとしてのマナーとなります。
8. 終わりに:KNApSAcKが切り拓く医療の未来
KNApSAcKは、日本が生んだ、世界に誇るべき知の遺産です。植物や微生物が数億年かけて進化させてきた「化合物のライブラリ」を、私たちはこのデータベースを通じて自由に閲覧し、医療に役立てることができます。これは、自然界の叡智と現代のデジタル技術が融合した、究極の形の一つと言えるでしょう。
医療関係者の皆様が、日々の診療や研究の中で「成分」や「エビデンス」の壁に突き当たったとき、ぜひこのKNApSAcKを思い出してください。そこには、新しい治療のヒントや、長年の疑問を解く鍵が隠されているかもしれません。ファーマAIラボでは、これからもこうした先端的な解析ツールと医療の接点を詳しくお伝えしていきます。
今回の記事が、皆様の専門領域における新たな発見の一助となれば幸いです。
免責事項
本記事は、KNApSAcKデータベースに関する情報の提供を目的としており、医学的アドバイスや特定の治療を推奨するものではありません。情報の正確性には万全を期しておりますが、科学技術の進展に伴い内容が変更される可能性があります。本記事の利用によって生じたいかなる損害についても、筆者およびファーマAIラボは責任は負わないものとします。実際の研究や臨床、商用利用にあたっては、必ず公式サイトの最新情報を確認し、自己責任においてご判断ください。
本記事は生成AI (Gemini) を活用して作成しています。内容については十分に精査しておりますが、誤りが含まれる可能性があります。お気づきの点がございましたら、コメントにてご指摘いただけますと幸いです。
Amazonでこの関連書籍「図とイラストで薬がみつかる わかる!漢方薬」を見る