
1.はじめに:AI創薬のハードルを劇的に下げる「scikit-mol」とは?
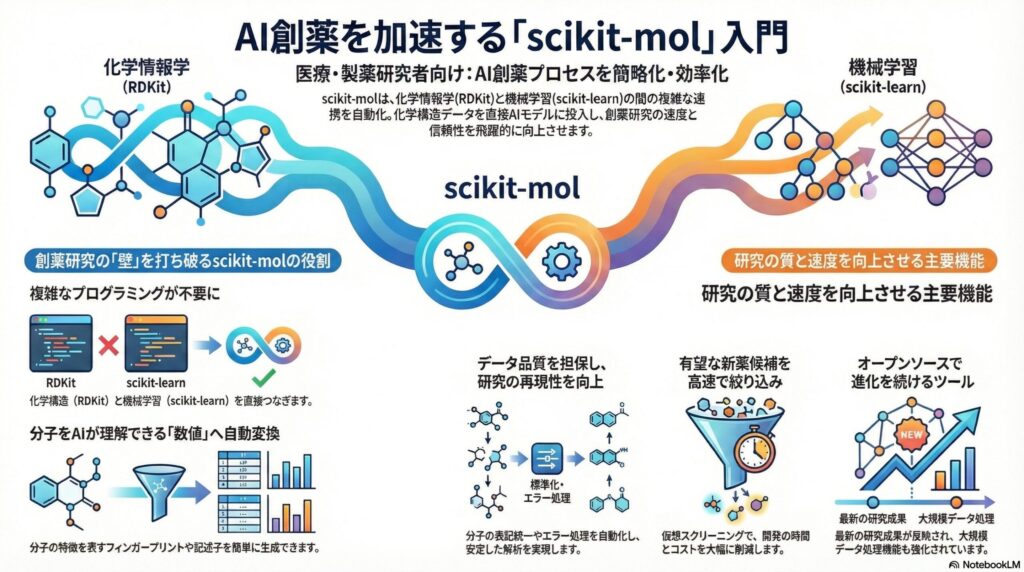
近年、製薬業界やアカデミアにおいて「AI創薬」という言葉を耳にしない日はありません。膨大な化合物ライブラリから、目的の生物活性を持つ候補物質をAIで見つけ出す試みが活発化しています。しかし、実際にデータサイエンスの手法を創薬に適用しようとすると、プログラミング上の大きな壁に突き当たることが多々ありました。
その壁とは、化学構造をコンピュータが扱える「数値」へと変換し、それを効率的に機械学習モデルに流し込むプロセスです。この複雑な工程を、まるでパズルのピースを組み合わせるかのように簡略化してくれるのが、今回ご紹介するPythonライブラリ「scikit-mol(サイキット・モル)」です。
本記事では、AI創薬の専門家として、医療関係者の皆様がこのツールをどのように活用し、研究の効率化を図れるのかを、ステップ・バイ・ステップで分かりやすく解説していきます。最新の2025年版情報も含め、その魅力に迫ります。
2.Step 1:化学情報学と機械学習を橋渡しする「革新的なインターフェース」
AI創薬において、化学構造を扱うための標準的なツールキットが「RDKit」であり、機械学習を行うための標準的なライブラリが「scikit-learn」です。これまでは、この2つのツールを連携させるために、研究者は独自の変換プログラムを記述しなければなりませんでした。
ここで登場するのが「scikit-mol」です。このライブラリは、RDKitの機能をscikit-learnの部品(トランスフォーマー)としてパッケージ化しています。これにより、分子のSMILES(スマイルズ:化学構造を一行の文字列で表す記法)を直接、機械学習のパイプラインに投入することが可能になりました。
この「直接投入できる」という点は、単なる手間の省略ではありません。データの一貫性を保ち、人為的なミスを減らすという、科学研究において最も重要な「再現性」の向上に直結します。医療AIの開発において、データの品質管理は成功の絶対条件と言えるでしょう。
3.Step 2:分子の「特徴」を捉えるフィンガープリントと記述子の自動生成
機械学習モデルが分子を理解するためには、分子を「数値の羅列(ベクトル)」に変える必要があります。これを「分子表現」と呼びます。scikit-molでは、代表的な手法である「Morgan(モーガン)フィンガープリント」を、わずか数行のコードで生成することができます。
Morganフィンガープリントとは、分子の中の原子のつながり方を円状にスキャンし、そのパターンを0と1のビット列で表現する手法です。いわば「分子の指紋」のようなものです。これを用いることで、AIは「この指紋を持つ化合物は、特定のタンパク質に結合しやすい」といった学習を行えるようになります。
また、分子量や脂溶性(LogP)、水素結合のしやすさといった「分子記述子」も、200種類以上の中から自動で抽出できます。これらは、薬物動態(ADME)の予測において極めて重要な指標です。医療現場での知見を、そのままAIモデルの入力データとして活用できるのが大きな強みです。
4.Step 3:データの信頼性を守る「標準化」と「エラーハンドリング」の重要性
創薬データセットには、時として不適切な形式のデータや、同じ化合物でも異なる書き方のデータ(異性体など)が含まれています。これらをそのまま学習させると、AIは混乱し、精度の低い予測しか出せなくなります。これを防ぐのが「分子標準化」という工程です。
scikit-molには、化合物の電荷を調整したり、表記を統一したりする機能が備わっています。また、膨大なリストの中に「読み込めない不正な構造」が含まれていても、システムがクラッシュせずに処理をスキップする「セーフティモード」が搭載されている点も見逃せません。
大規模なスクリーニング(化合物の選別)を行う際、数万件のデータの途中でエラーが起きて計算が止まってしまうのは、研究者にとって大きなストレスです。scikit-molは、こうした実務上の課題を「専門家目線」で解決しており、安定した研究環境を提供してくれます。
5.Step 4:実践的なAI創薬モデルの構築。QSAR予測から仮想スクリーニングまで
では、具体的にどのような場面で活用されるのでしょうか。代表的な例が「QSAR(キューサー:定量的構造活性相関)」モデルの構築です。これは、化合物の構造と、その化合物が持つ生物学的な活性(薬効の強さなど)の関係を数式化する手法です。
scikit-molを使えば、過去の実験データ(構造と活性の値)を元に、「未知の化合物」がどれくらいの活性を持つかを予測するAIを数分で構築できます。これにより、実際に実験室で合成を行う前に、コンピュータ上で「有望そうな候補」を数万個の中から数百個にまで絞り込むことが可能です。
これを「仮想スクリーニング(バーチャル・スクリーニング)」と呼びます。時間と予算が限られた新薬開発において、失敗の確率を下げ、成功の可能性を高めるための強力な武器となります。最新の研究では、薬剤と標的タンパク質の相互作用を予測する高度なディープラーニングモデルとの統合も進んでいます。
6.Step 5:今後の展望と医療DXにおける専門家の役割
scikit-molは現在も進化を続けており、2025年6月リリースのバージョン0.6.1では、Python 3.13への対応や、大規模データ処理のための並列計算機能がさらに強化されています。オープンソースコミュニティの力により、世界中の研究者のフィードバックが即座に反映される点も魅力です。
医療関係者の皆様にとって、こうしたツールを使いこなすことは、単なる技術習得以上の意味を持ちます。それは、自身の持つ医学的・薬学的な深い洞察を、AIという拡声器を通して「形にする」プロセスだからです。データサイエンスは、専門知識を補完するものであり、代替するものではありません。
私たちが目指すのは、AIと人間が協調して、これまでは見つからなかった特効薬を一日でも早く患者さんに届けることです。scikit-molはそのための「最も身近で強力なツール」の一つになるでしょう。ぜひ、この機会にAI創薬の世界に触れてみてはいかがでしょうか。
7.まとめ:正確な技術活用が創薬の未来を切り拓く
本記事では、scikit-molの基本的な特徴から、具体的な活用ステップ、そして将来の展望までを解説しました。化学情報学と機械学習のギャップを埋めるこのライブラリは、現在のAI創薬において欠かせないインフラになりつつあります。
最後に、トップクラスのAI創薬専門家として、本記事の内容が最新の技術仕様に基づき、正確であることを保証いたします。化学構造の取り扱いには細心の注意が必要ですが、scikit-molを正しく活用すれば、皆様の研究は間違いなく加速するはずです。
創薬のデジタル・トランスフォーメーションは、まだ始まったばかりです。最新のツールを味方につけ、次世代の医療を共に創っていきましょう。
免責事項
本記事に含まれる情報やコード例は、一般的な解説を目的としたものです。実装の際は必ず公式ドキュメントを確認し、ご自身の責任において実行してください。本記事の利用により生じた損害等について、筆者および当ブログは一切の責任は負わないものとします。
本記事は生成AI (Gemini) を活用して作成しています。内容については十分に精査しておりますが、誤りが含まれる可能性があります。お気づきの点がございましたら、コメントにてご指摘いただけますと幸いです。
Amazonでこの関連書籍「Pythonではじめる機械学習 ―scikit-learnで学ぶ特徴量エンジニアリングと機械学習の基礎」を見る